Agile Studio見学への要望を機械学習で分析してみた
はじめに
こんにちは。永和システムマネジメント FDPメンバの坂部です。
今回、Agile Studio 見学への要望のデータを、クラスタリングすることで分析してみました。
Agile Studioとは?
Agile Studioは、永和の、アジャイル開発を推進するサービスです。 企業様に向けて、仕事の様子を見たりアジャイル開発についてディスカッションしたりする見学会を開催しています。 今回分析するデータは、この見学の事前アンケートを元にしています。
やったこと
データを整形する
データを眺める
まずは、データを眺めました。
データは、見学する企業様ごとにスプレッドシートにまとまっています。
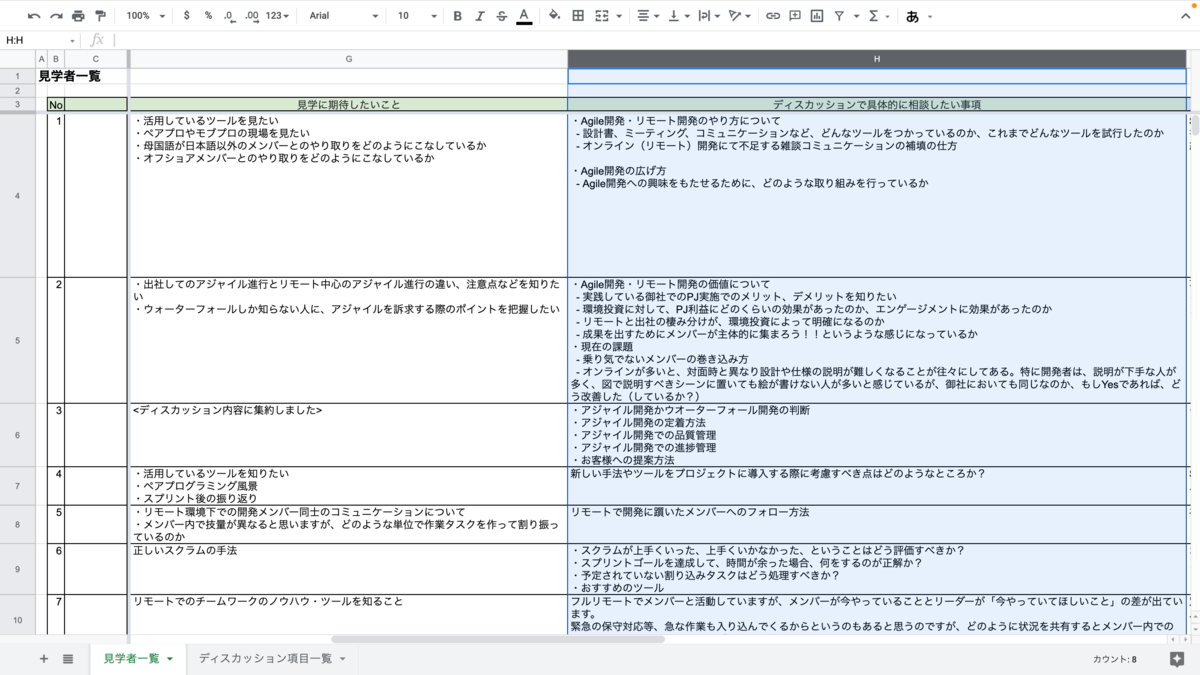
複数の項目があるのですが、今回は「ディスカッションで具体的に相談したい事項」について分析することにしました。 なお、これ以降、「ディスカッションで具体的に相談したい事項」は「質問」と呼ぶことにします。
データをファイルにまとめる
そこまで量がなかったので、手作業でスプレッドシートから「ディスカッションで具体的に相談したい事項」を抜き出し(as 質問)、一つのスプレッドシートにまとめ、csvでエクスポートしました。
質問を分割する
ここからPythonで作業していきます。
import pandas as pd # 先ほど作成したcsvを読み込む df = pd.read_csv('./data.csv', header=None, names=['質問']) df

スプレッドシートのセル一つ一つから抜き出しましたが、セル一つに複数の事項が存在するセルもあったので、下記のようなデータが含まれています。

これらは、コードで分割しました。
import re def split_to_single_question(target): for bullet_mark in '①', '②', '③', '-': target = target.replace(bullet_mark, '・') # 「・」の前に改行を含むものだけを対象として分割する。 # 含まないものは、箇条書きを意味する「・」ではないと捉えて、分割しない # 改行と「・」の間の半角スペースは無視する pattern = "\n\s*・" if re.search(pattern, target) is None: return [target] target_split = re.split(pattern, target) if target_split[0][0] == "・": return target_split else: # 箇条書き一つ前の文は、全ての箇条書きの先頭に付与する return [target_split[0] + ", " + t for t in target_split[1:]] split_questions = [] for questions in df["質問"]: for q in split_to_single_question(questions): split_questions.append((questions, q)) df = pd.DataFrame(split_questions, columns=["質問", "分割済み質問"]) df

また、下記のように永和からの回答が含まれている場合もあります。

これらは、コードにて回答の部分を削除しました。
def remove_response_from_eiwa(target): for response_mark in ["⇒(ESM)", "⇒ (ESM)", "→"]: target = target.split(response_mark)[0] return target df["分割済み返答削除済み質問"] = df["分割済み質問"].map(remove_response_from_eiwa) df

パターンの漏れがあり、これらで全ての質問を分割したり、全ての回答を削除したりはできませんが、 とりあえずヨシとします 👈🏼 🐱
クラスタリング
では、クラスタリングしていきましょう。
質問から単語を抜き出す
まずは、質問から単語を抜き出します。
今回は、Mecabという形態素解析エンジンで品詞に分解しました。 解析用の辞書はIPADICを採用しています。(実はIPADICはサポート終了してる 😭 )
分解後、名詞かつ意味のある単語だけを抜き出します。
import requests import MeCab import ipadic # 今回の処理において意味のない単語リスト(=ストップワード) stop_words = [] # ある程度のストップワードは、ここでリストが提供されている SLOTHLIB_URL = "http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt" stop_words.extend(requests.get(SLOTHLIB_URL).text.split("\r\n")) # slothlibで対応できないものは、手動で対応 stop_words.extend(['0', '1', '2', '3', '4', '5', '6' '7', '8', '9']) stop_words.extend(['0', '1', '2', '3', '4', '5', '6' '7', '8', '9']) stop_words.extend(['あ', 'い', 'う', 'え', 'お', 'か', 'き', 'く', 'け', 'こ', 'さ', 'し', 'す', 'せ', 'そ', 'た', 'ち', 'つ', 'て', 'と', 'な', 'に', 'ぬ', 'ね', 'の', 'は', 'ひ', 'ふ', 'へ', 'ほ', 'ま', 'み', 'む', 'め', 'も', 'や', 'ゆ', 'よ', 'ら', 'り', 'る', 'れ', 'ろ', 'わ', 'を', 'ん']) stop_words.extend(['が', 'ぎ', 'ぐ', 'げ', 'ご', 'ざ', 'じ', 'ず', 'ぜ', 'ぞ', 'だ', 'ぢ', 'づ', 'で', 'ど', 'ば', 'び', 'ぶ', 'べ', 'ぼ']) stop_words.extend(['方', '方法', 'こと', 'ため', '人', '性', '何', '等', '化', '場合', '点', '時', '工夫', '様', '中', 'とき', 'ところ', 'もの', 'それ', '書', '側', '内', '際', '以下', '20', '年', 'M', '内容', '作成', '.', 'どこ', '以外', 'つ', '目', 'さん']) stop_words.extend(['アジャイル', 'Agile', '開発']) # かなり多く出てくるので削除 mecab_tagger = MeCab.Tagger(ipadic.MECAB_ARGS) def parse_question_to_words(target): parsed_lines = mecab_tagger.parse(target).split('\n') parsed_words = [parsed_line.split('\t') for parsed_line in parsed_lines] words = [] for parsed_word in parsed_words: if len(parsed_word) > 1 and '名詞' in parsed_word[1]: target = parsed_word[0] # ストップワードに含まれない単語だけを取り扱う if not target in stop_words: words.append(target) return words df['単語'] = df['分割済み返答削除済み質問'].map(parse_question_to_words) df

質問をベクトル化する
単語をもとに、それぞれの質問をベクトル化していきます。
今回は、それぞれの単語の出現回数を、質問を表すベクトルとしました。
また、そのベクトルをtf-idfで重み付けしました。(tf-idfの説明は、自信ないのでwikipediaに任せます…)
from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer # ベクトル化 bags = CountVectorizer().fit_transform([" ".join(words) for words in df["単語"]]) # ベクトルを重み付け tf_idf = TfidfTransformer(use_idf=True, norm="l2", smooth_idf=True).fit_transform(bags)
質問をクラスタリングする
k-means法でクラスタリングしてみます。(この説明もwikipediaで…)
from sklearn.cluster import KMeans kmeans_model = KMeans(n_clusters=10, random_state=1) # クラスタ数は10で固定 result = kmeans_model.fit_predict(tf_idf)
結果を描画する
クラスタごとの要素数をグラフで見てみましょう。
import collections import matplotlib.pyplot as plt cluster_count = dict(collections.Counter(result).most_common()) cluster_count_sorted = sorted(cluster_count.items(), key=lambda x: x[0]) k = [f"クラスタ {k}" for k, _ in cluster_count_sorted] v = [v for _, v in cluster_count_sorted] plt.figure(figsize=(20, 20), dpi=50) plt.bar(k, v)
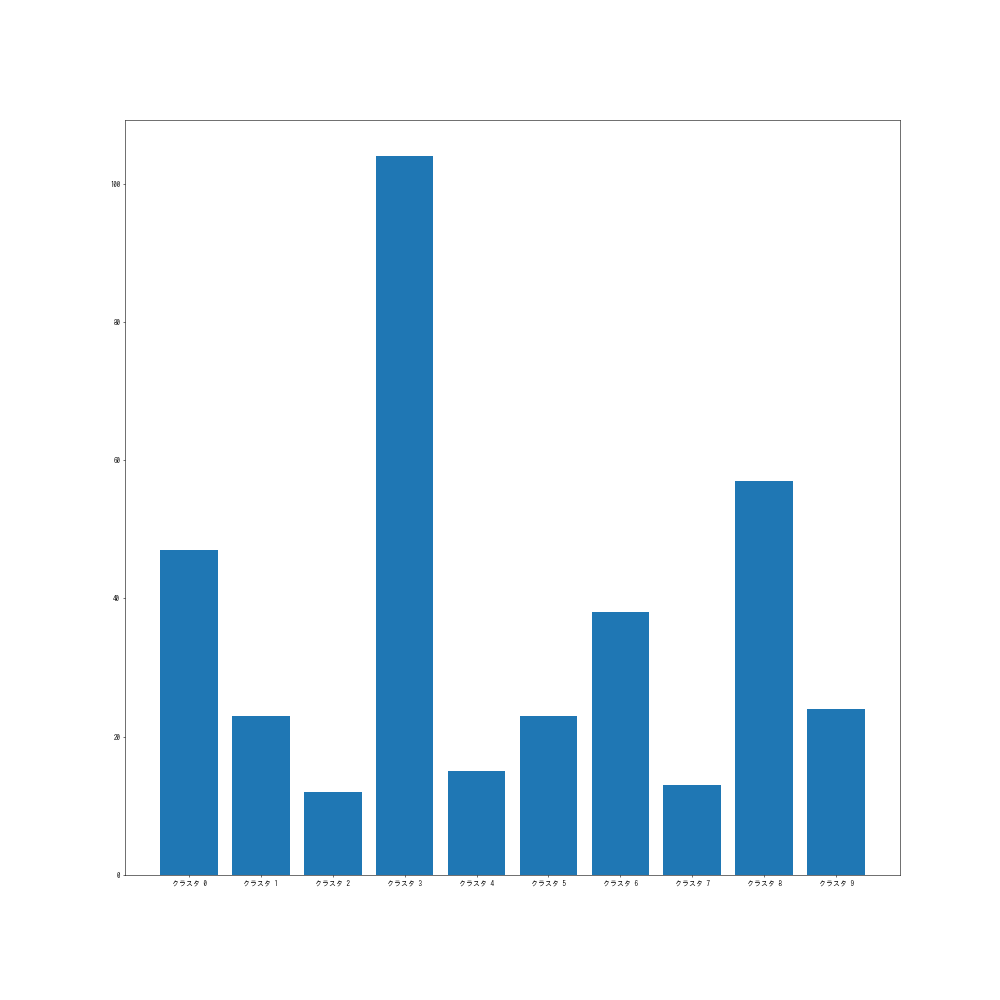
まあまあ分散した結果になったのではないでしょうか。
クラスタごとにどんな単語が含まれているか見てみましょう。
df["クラスタ"] = result cluster_words_dict = {} for i, row in df.iterrows(): cluster, words = row["クラスタ"], row["単語"] if cluster in cluster_words_dict: cluster_words_dict[cluster].extend(words) else: cluster_words_dict[cluster] = words cluster_commonwords_dict = {} for k, v in cluster_words_dict.items(): counter = collections.Counter(v) # クラスタの頻出頻度上位10単語を参照 cluster_commonwords_dict[k] = dict(counter.most_common(10)) fig, ax = plt.subplots(10, figsize=(50, 50)) for k, v in cluster_commonwords_dict.items(): ax[k].set_title(f"クラスタ {k}") ax[k].bar(v.keys(), v.values())
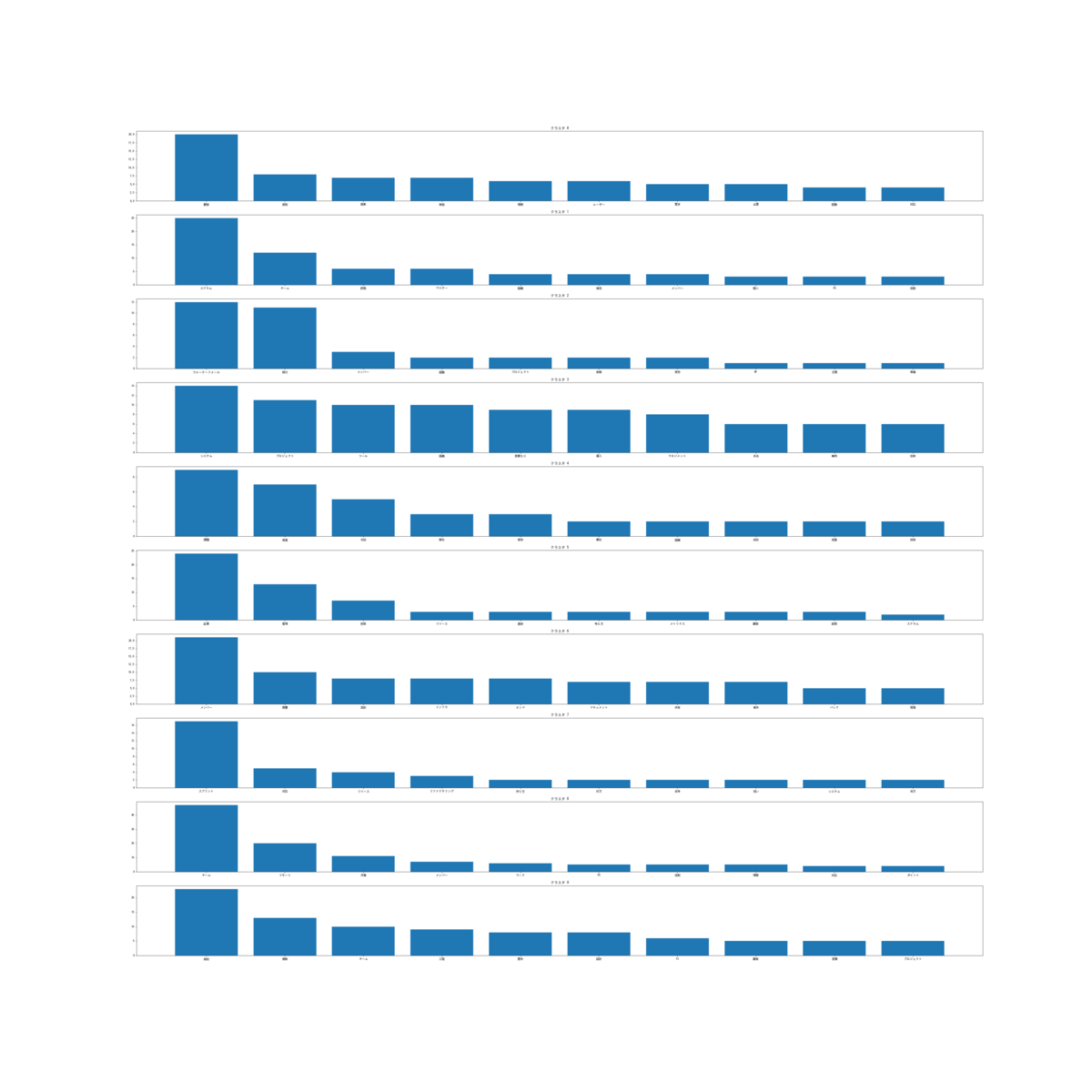
見辛いですね…ワードクラウドを描画してみましょう。
word_cloudを使います。
from wordcloud import WordCloud fig, ax = plt.subplots(nrows=4, ncols=3, figsize=(50, 50)) for k, v in cluster_commonwords_dict.items(): wordcloud = WordCloud().fit_words(v) ax_item = ax.ravel()[k] ax_item.set_title(f'クラスタ {k}', fontsize=100) ax_item.set_axis_off() ax_item.imshow(wordcloud, interpolation='bilinear')

なんとなく「クラスタ2はウォーターフォールからの移行に関して」「クラスタ8はリモートでのコミュニケーションに関して」など意味のあるクラスタになってそうですね。
感想
2週間、こちらの課題に取り組んでみたのですが、とりあえず一通りのプロセスを動かすために、アルゴリズムやコードの精査を省いています。それらを精査してもっと適切な方法を学びたいです。
また、実際に課題にトライすることで、機械学習プロジェクトの流れが少し掴めた気がします。