教師あり学習で分類をやってみた
はじめに
Agile Studioの岡本です。
毎回自己紹介の文言が揺れている気がします。
坂部さんが書いてくれたこちらの続きです。
前回はクラスタリングでしたが、今回は分類をやってみます。
クラスタリングと分類
クラスタリング
与えられた情報を、データの持つ特徴からいくつかのグループに分ける。
どう分けるか?は指示できず、分けた結果にも絶対的な正解はない。
(なので前回の結果も全体を眺めて「何となく良さそう」位しか言えない)
正解がないので「教師なし学習」の一種
分類
与えられた情報を、事前に正解が決まっているどのラベルに所属するか予測する。
正解があるので「教師あり学習」の一種
ながれ
まず最初に、全体の流れはこんなイメージです。
以下、これに沿って説明していきます。

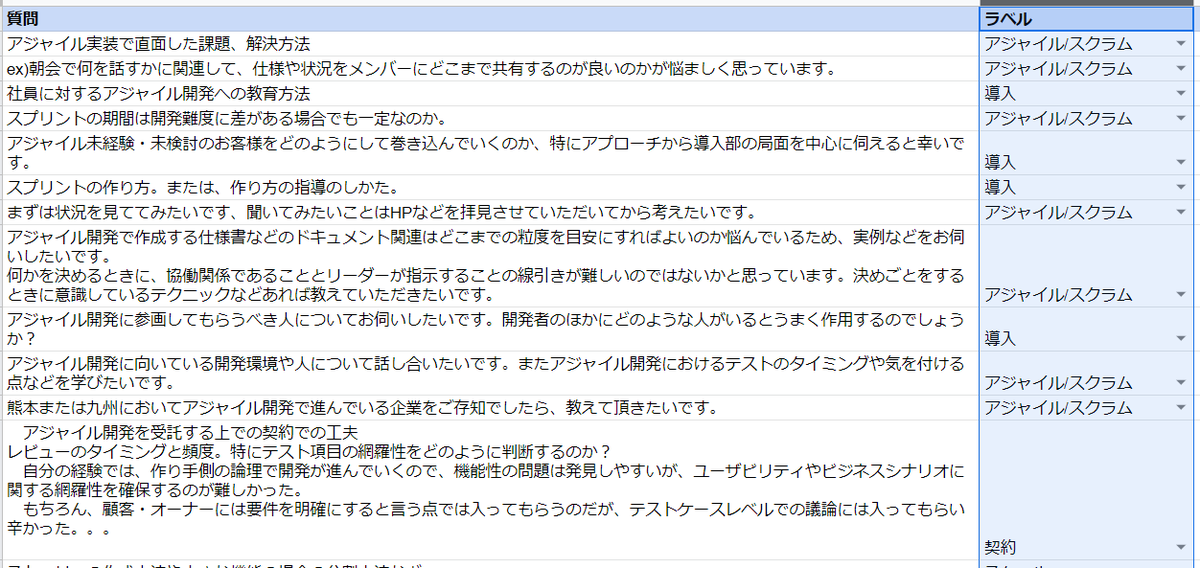
質問に対してラベル(正解となる分類)を付ける
まずは各質問に対して、「どのように分類されるべき」というラベルを設定します。
これは人間が手作業で行うため、作業者の主観が入ることもあり、正直一番難しい所です。
(後で思い知ることになります)
今回は岡本が独断で以下のような 10 個の分類を行いました。
- 契約
- 品質
- ウォーターフォール
- チーム
- ロール
- マネジメント
- 導入
- スケール
- アジャイル/スクラム
- リモート
手で入れた(ここはエクセル仕事です。。)
(途中省略)
質問を整形/分割して単語を抜き出すまでの処理は、前回のクラスタリングと共通なので説明は省略します。
ラベルを数値化する
ラベルを数学的に扱うために数値化します。
機械学習用語で「カテゴリ変数をダミー変数化する」とも言います。(難しい言い方だ)
ダミー変数化する方法として、pandas の get_dummies を用いるOne hot Encodingがあり、ググるとこれが多くヒットしますが、多値変数を扱う場合には複数のダミー変数が出現してしまうのであまり望ましくないらしいです。
そこでここでは Label Encoding によるダミー変数化を行います。
sklearn に専用のライブラリがあるのでそれを使えば簡単です。
これだけで OK
le = preprocessing.LabelEncoder() df['label'] = le.fit_transform(df['ラベル'].tolist())
こうなる

教師データとテストデータに分割する
全体を
- 教師データ:モデル学習のために使う部分
- テストデータ:学習した結果の評価(答え合わせ)に使う部分
に分割します。
またこれだけ。
train_df, test_df = train_test_split(df, random_state=0, train_size=0.3)
詳細は分からなくても何となくやっていることが想像できると思います。
質問をベクトル化して学習する
ベクトル化
質問(正確には質問から抽出した単語の集まり)も数学的に扱うために数値化します。
ラベルのように単純な数値化(10 種類のラベルを 0 ~ 9 に割り当てる)のではなく、質問の持つ特徴を抽出する必要があり、これをベクトル化と言います。
ベクトル化にはいろいろな手法(アルゴリズム)があるのですが、ここでは簡単に質問の中に登場する回数を特徴として抽出する CountVectorizer という手法を利用します。
学習
更にベクトル化した質問とそのラベルの対応関係を学習してモデルを構築します。
この学習の手法(アルゴリズム)もいろいろあり、データの特性にあった選択をするのがキモのようです。
ここではscikit-learn アルゴリズム・チートシート scikit-learn.org
を参照して ナイーブベイズ法 を使うことにします。
長々と説明しましたがコードはこれだけです(scikit-learn のライブラリがすごい)
model = make_pipeline(CountVectorizer(), MultinomialNB()) model.fit(train_df['data'], train_df['label'])
学習したモデルを使って分類(予測)を実行する
モデルができたので、これを使って実際に分類してみます。
分類は、モデルの学習に使わなかった方(テストデータ)で行って評価するのですが、モデルの良し悪しを見るために教師データの方でもやってみます。
教師データの分類実行と評価
train_df['pred'] = model.predict(train_df['data']) train_score = model.score(train_df['data'], train_df['label']) print(f'教師データのスコア:{train_score}')
評価結果
教師データのスコア:0.9512195121951219
教師データの分類実行と評価
test_df['pred'] = model.predict(test_df['data']) test_score = model.score(test_df['data'], test_df['label']) print(f'テストデータのスコア:{test_score}')
評価結果
テストデータのスコア:0.5
スコアの見方
0 ~ 1 の間で数値の大きい方が優秀(正解率が高い)です。
モデルを作るのに使った教師データなので、これを予測すれば100%正解しそうなものですが、そうはならないようです。
一方で答えの分かっていないテストデータに対しては、かなり正解率が落ちてしまっています。
これは、教師データの特徴を過度に学習してしまい、その他のデータに対して汎用的には使えないようなモデルになっている可能性を示しています。
この状態を「過学習」と言います。
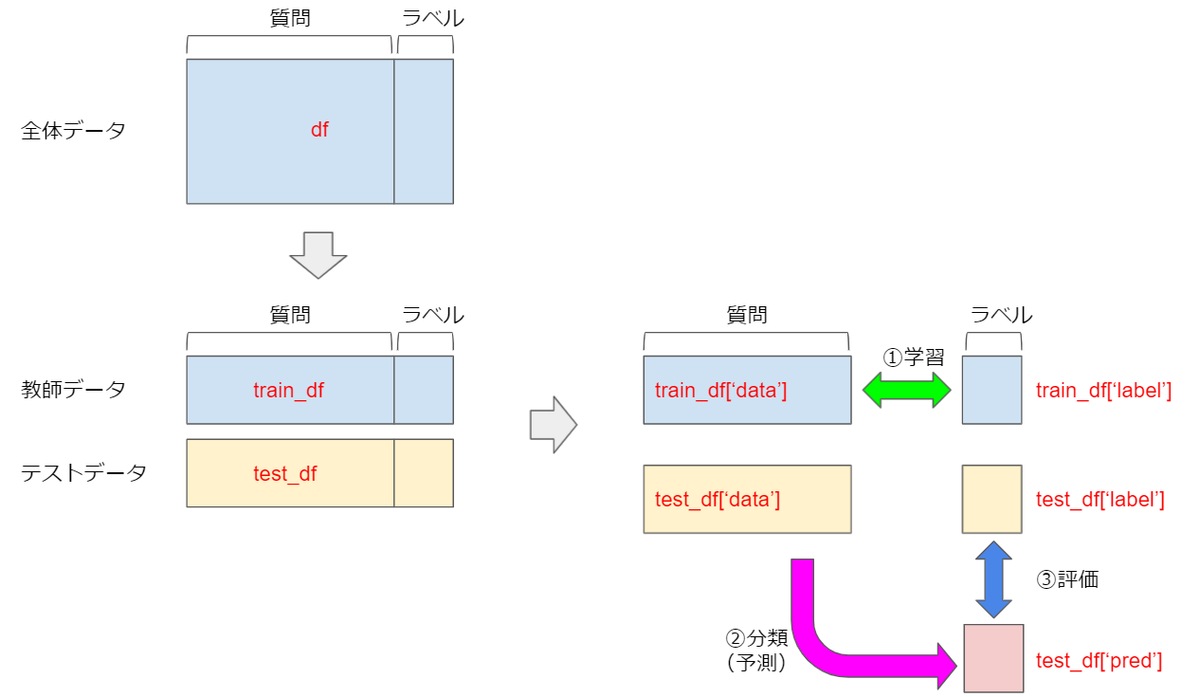
データの流れ(再掲)
コードとの対応関係を記したデータの流れを再度記載しておきます。
分類結果を評価する
これだけではモデルの良し悪しが分かりにくいので、正解ラベルと予測ラベルの対応を混同行列を使って描画してみます。
ここでは seaborn
というグラフライブラリを使っています。
またもこれだけ。
mat_train = confusion_matrix(train_df['label'], train_df['pred'])
mat_test = confusion_matrix(test_df['label'], test_df['pred'])
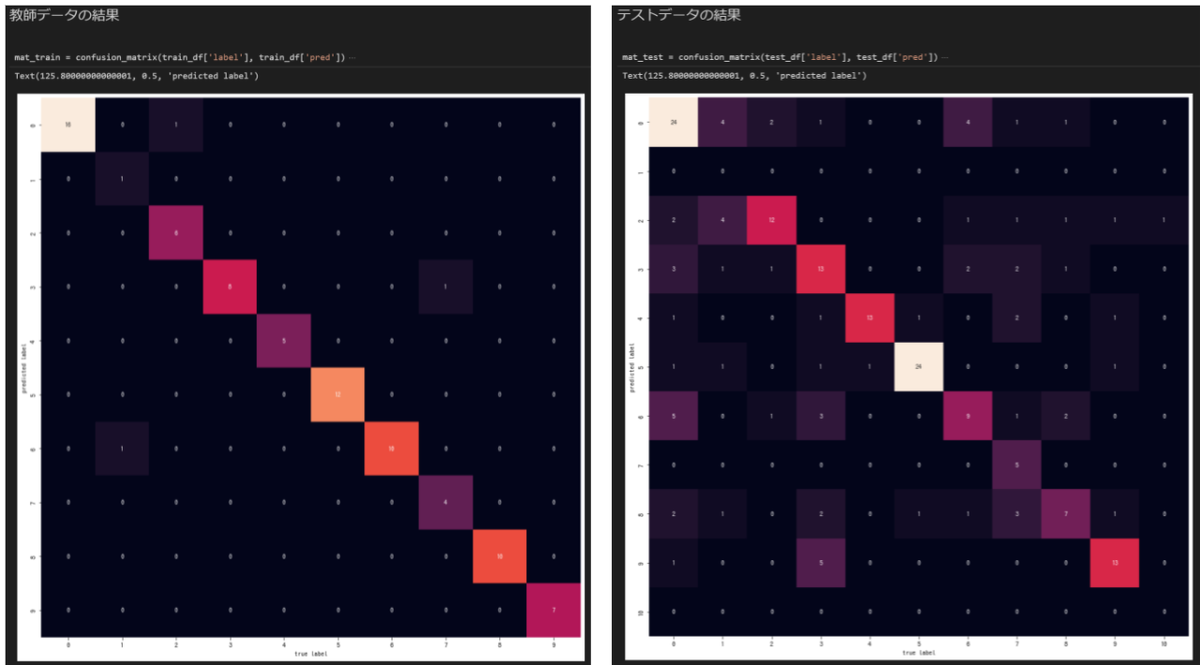
左が教師データ、右がテストデータの分類結果です。

グラフ(混同行列)の見方
横軸が正解ラベル、縦軸が分類(予測)されたラベルになっています。
予測結果が正解と同じだと対角線上に綺麗にプロットされることになります。
左の教師データは割と綺麗ですが、右のテストデータは多くの質問を1のラベルだと誤判定しています。
上で求めたスコアの傾向とも一致していて、あまりよろしくない結果のようです。
ちょっと考察
分類の精度が悪い理由は色々と考えられます。
- 学習対象のデータ量が少ない
- 学習対象のデータに有意な特徴がない
- ベクトル化のアルゴリズム選定、パラメータ調整が悪い
- 学習のアルゴリズム選定、パラメータ調整が悪い
- 人間がやったラベル付けが悪い(!!!)
本来であればこれらに対しての分析&トライを繰り返して精度を上げていく(そのためにも分類の良し悪しを定量的に測定できるスコアがとても大事)のですが、今回は時間がない事もあり、そもそも一番怪しいと思われる 『人間がやったラベル付けが悪い』 を疑ってみます。
別のアプローチを試してみる
前回のクラスタリングで、機械学習によってクラスタリングを行った結果、まあまあ良さげなグループ分けが出来ていました。
そこで、岡本が付けたラベルの替わりに、このグループ分けの結果を正解ラベルとして使ってみます。
具体的にはこの 1 行を変更します。
これを
df['label'] = le.fit_transform(df['ラベル'].tolist())
こうする
df['label'] = le.fit_transform(df['クラスタ'].tolist())
クラスタの列には前回のクラスタリングで得られたグループ情報が入っています。
再度評価してみる
評価結果(教師データ)
教師データのスコア:0.9634146341463414
評価結果(テストデータ)
テストデータのスコア:0.6185567010309279
教師データはそれほど変化しませんがテストデータは大きく向上しています。
続いて混同行列も見ます。
こんどは右のテストデータでも、そこそこ綺麗に対角線上に乗っていて、前回よりも精度が上がったように見えます。
やはり人間の行ったラベルに付けに問題があったようです。
感想
- scikit-learn のライブラリはすごい
データ処理やグラフ描画を除いた機械学習の本体はここに記載した数行のコードで実行できます。
「機械学習をやるなら Python」と言われている理由が良く分かります。 - Pythonのプロになる必要はない
機械学習で必要になるのは、使うライブラリをインポートして、そのライブラリを良い感じに使って、処理をコンパクトにするために簡単な繰り返しや条件分岐の構造が書ける、位です。
Python初学者でも問題なくトライできます(他の言語を触ったことがあれば尚更) - 数値化/評価まで含めた自動実行の仕組み大事
最後は精度向上のためにトライ&確認を繰り返すことになるので、評価までが自動で行えるかどうかが作業効率にモロに効いてきます。
初回は面倒でも手作業を無くしてコード化して置くことが大事です(ユニットテストと同じですね) - 人間の作業が一番信用ならない
ラベル付けに限らずデータの整形(クリーニング)など、機械学習の前段で行う作業によって結果が大きく変わってくるので、意外に原始的な作業の良し悪しが大事かも。
次回
次は回帰にチャレンジしているので、また一段落したら別の記事に書こうと思います。