朝会のファシリテータ当番を通知する Slack Bot を作ってみた
こんにちは。永和システムマネジメント FDPメンバの坂部です。
最初は Express.js を使っていましたが、Slack Bot 用フレームワークの Bolt が案外使いやすそうだったので、移行しました。
きっかけ
今まで、手作業で miro のふせんを貼り替えて、朝会のファシリテータを管理していました。

ただ、この方法だとふせんの移動を忘れることがありました。
そこで、Slack Bot で自動化することにしました。
作ったもの
毎朝、ファシリテータ当番にメッセージを送信します。

また、Slack のコマンドで /members と入力すると、登録されているメンバ一覧を確認できます。

他にも、下記のコマンドに対応しています。
| コマンド | 内容 |
|---|---|
| /add | 自身をメンバに追加 |
| /delete | 自身をメンバから削除 |
| /add |
指定した ID のユーザをメンバに追加 |
| /delete |
指定した ID のユーザをメンバから削除 |
| /skip | "次のファシリテータ"を更新 |
| /notify | ファシリテータ通知を手動で発火 |
| /members | 登録メンバ一覧と次のファシリテータを表示 |
こんな感じで書いていきます
毎朝の通知は、Heroku Scheduler でスクリプトを起動して、Slack Bot の Incoming Webhook に投げることで、実行しています。
import { fetchAndUpdateFacilitator } from "..."; import got from "got"; import * as holiday_jp from "@holiday-jp/holiday_jp"; async function main() { const today = new Date(); // Sunday or Saturday or Holiday if (today.getDay() == 0 || today.getDay() == 6 || holiday_jp.isHoliday(today)) { return; } // From DB const slackMemberId = await fetchAndUpdateFacilitator(); // SLACK_WEBHOOK_PATH は事前に Slack アプリの画面でぽちぽちして生成されるやつ const url = `https://hooks.slack.com${process.env.SLACK_WEBHOOK_PATH}`; // Incoming Webhook にリクエストを投げる try { await got.post(url, { json: { text: `<@${slackMemberId}> 今日のファシリテーターです` }, }); } catch (error) { console.error(error); } } main();
Slack のコマンドを受け付ける Bolt アプリはこんな感じです。
import { App } from "@slack/bolt"; import { fetchUserList } from "..."; // Bolt のアプリを作成 const app = new App({ // SLACK_BOT_TOKEN と SLACK_SIGNING_SECRET は Slack アプリ作ったときに生成されるやつ token: process.env.SLACK_BOT_TOKEN, signingSecret: process.env.SLACK_SIGNING_SECRET, }); // membersコマンドを受け付ける app.command("/members", async ({ ack, respond }) => { // コマンドのリクエストを承認 await ack(); // From DB const userList = await fetchUserList(); const usersText = userList .map((user) => (user.isFacilitator ? `${user.userName} <== 次のファシリテータ` : `${user.userName}`)) .join("\n"); await respond({ // Slackで "ユーザの一覧です…" と応答する text: `ユーザの一覧です\n\n${usersText}`, // 応答をチャンネルに投稿して、コマンド送信者以外にも見えるようにする response_type: "in_channel", }); }); // アプリを起動 (async () => { await app.start(parseInt(process.env.PORT || "3000", 10)); console.log("⚡️ Bolt app is running!"); })();
所感
Slack Bot(に限らず Bot 全般) を初めて作ったのですが、シンプルな機能なら案外簡単に作れるんだなーとわかりました。
これからも、ちょっと Bot ほしいなと感じたら作っていこうと思います。
早くも今年をふりかえる
はじめに
岡本です。
ブログが始まってまだ5日目ですが早くもふりかえりですw
実はFDPの活動は10月からスタートしていて、ここに載せるのが追い付いていないのですが、仕事納めに年末らしいエントリが欲しくなったので概要だけ書いてみます。
それぞれについては後で詳細なエントリが出てくるかもしれません(メンバの皆さんに期待!)
これまでのあらすじ
10月
キックオフ

読書
メンバが全員揃って『機械学習って何?』というレベル0からのスタートなので、とりあえず本を買って読んでみます。
そもそもどんな本を読んだらいいかも分からないので、全員でググってそれらしい本を2冊読んでみました。


とてもラッキーなことに『勉強のためなら金に糸目は付けない(意訳)』という会社の方針を頂き、その後も月に数冊のペースでメンバが好きな本を買って読んでいます。
動画
同時にAIの基礎について評判の良い動画があると聞いたので、これも全員で視聴しました。
これは分かりやすくて良かったです。
ワーク#0(タイタニック)
機械学習のHello World的な、Kaggleのタイタニック問題をやってみました。
- データ取得
- モデル構築
- 学習
- 予測
- 評価
といった機械学習の基本のキがなんとなくイメージできるようになりました。
さすがハローワールドです。
11月
環境構築
タイタニックは初心者らしくGoogle Colaboratory を使いましたが、ソフト開発屋らしくコード管理したい!ということで、docker container + VS Code + Git/Github を使った開発環境を作ってみました。
機械学習とソフト開発の文化の違いみたいなものも見えてきて、なかなか興味深い学びがありました。
ワーク#1(クラスタリング)
そろそろ何か実践として手を動かしたいということでPOがお題を持ってきてくれました。
弊社のAgile Studioではリモート見学会というのを随時開催しているのですが、参加者から頂いた評価アンケートのデータが膨大でとても手作業で分析できないという事で、これを機械学習を使って改善できないか?という物です。
スプレッドシートに書かれた日本語のコメントを扱うので自然言語処理にも少し触れることが出来ました。

ワーク#2(分類)
今度は同じお題を分類という手法を使って分析してみます。
『分類とクラスタリングって何が違うの?』がようやく理解できるようになりました。
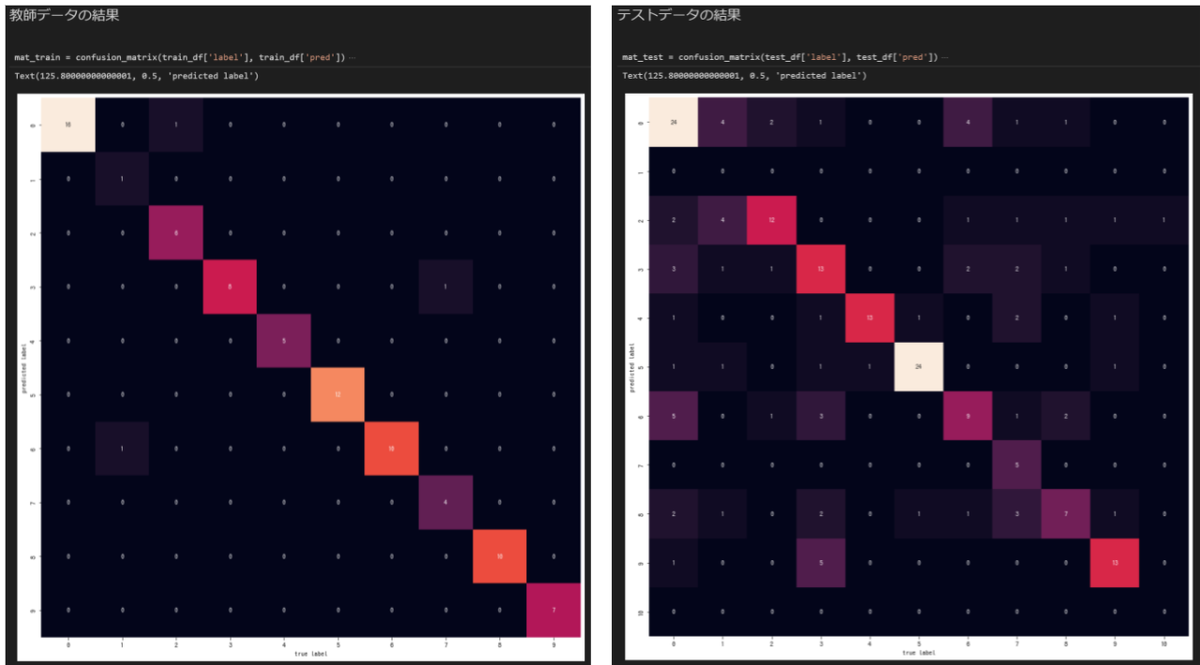
ワーク#3(回帰)
クラスタリング、分類と来たので今度は回帰をやってみようかということで、再びKaggleから適当なお題を選んでトライしてみます。
100,000 UK Used Car Data setwww.kaggle.com
これまではネットにあるサンプルコードや、やってみました系の情報をほぼ写経に近い形で参考にしていたのですが、ここでは少し自分たちで考えて、色々な回帰のアルゴリズム比較に挑戦してみました。

公開スクラム
私たちのチームでやっている日々のスクラムを公開してみました。
朝会とふりかえりとモブプログラミングの様子を生中継しながら実施、緊張しました~
12月
オンボーディング
ここで新しく三田村さんがジョインしたので再スタートの意味も込めてオンボーディングをやってみました。(キックオフ参照)


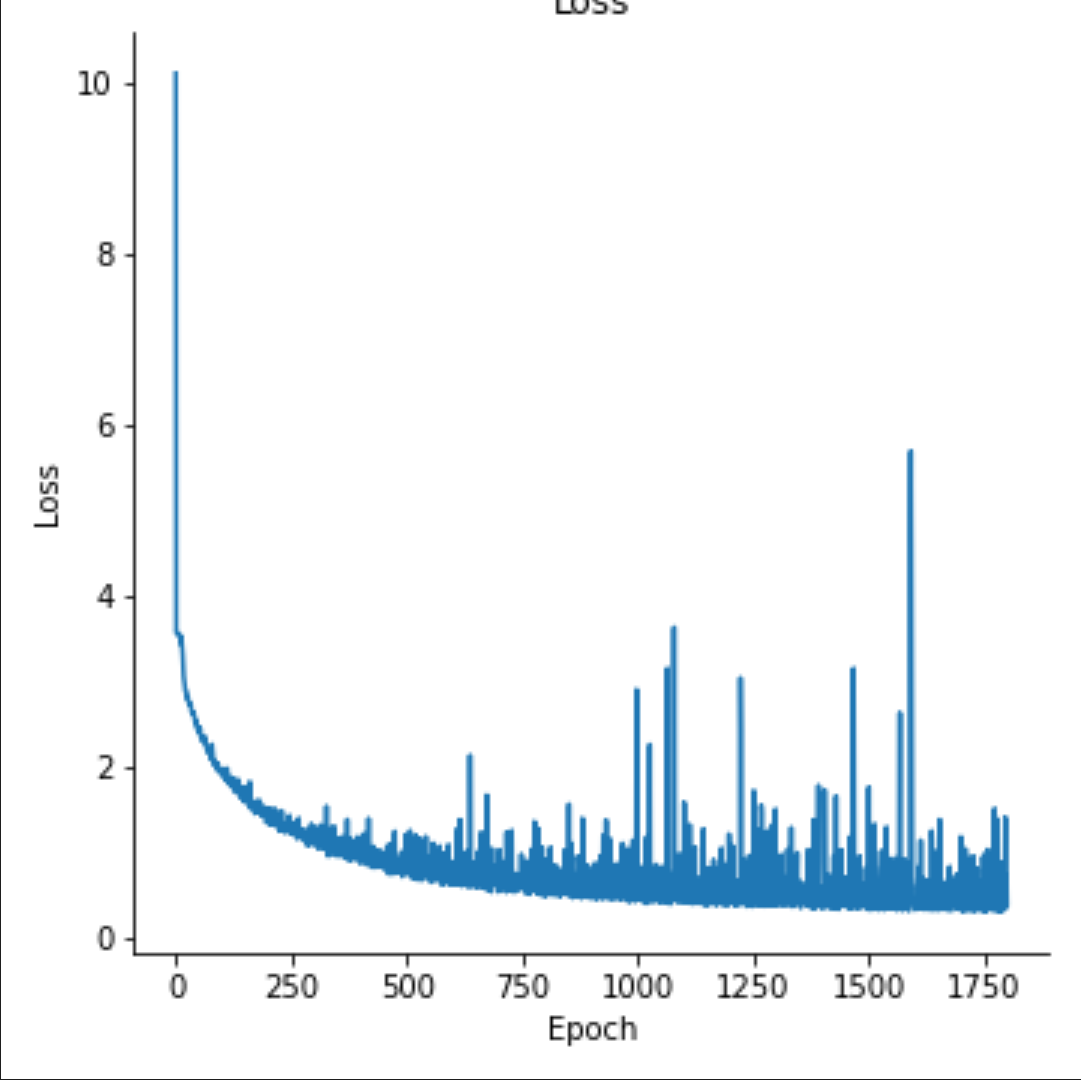
ワーク#4(画像分類 with ニューラルネット)
3か月目に入りまた新しい領域に手を出してみたい!ということで、今度はニューラルネットに挑戦してみます。
これまたKaggleから適当なお題を選んでトライです。
Fruit and Vegetable Image Recognitionwww.kaggle.com
ここで初めての挫折!!
ここまでは比較的順調に進んでいた(やってみたら一発でそれらしい結果が出た)のですが、ここにきて壁に突き当たります。
学習しても予測精度が2%台とかでサッパリ結果が出なくなってしまいました。
色々と調べた結果、最終的には学習回数やパラメータ調整によって結果が大きく変動することがわかりホッと安心しました(いい成績が出た訳ではない)が、何となく雰囲気でやっていてもダメなことを痛感し身が引き締まる思いでした。


おわりに
改めてふりかえってみるとたった3か月ですが色々やってきたなあ、という気持ちになります。
今年いっぱいで大枠としての学習期間は終了し、来年の1月からはFDPとして本格的なプロダクト開発をスタートします。
また新しいネタが沢山出てくると思いますので、チームの成長と共にここに記録していこうと思います。(メンバの皆さんに期待!2回目)
今年一年、ありがとうございました!
来年もよろしくお願いします!!
チームビルドをやってみた
はじめに
岡本です。
10月からFDPの活動を始める時にまず最初にやったチームビルドについて紹介してみます。
登場人物
チームメンバの4人はほぼ初対面でした。
(金融事業メンバのお二人だけはお互いに知っている)
 坂部(DEV)
坂部(DEV)
ITサービス事業部
社会人としてのソフトエンジニア歴は1年未満
今年の新卒入社
Agileネイティブ世代
チームで一番沢山&カッコいいコードを書きます
 岡本(SM兼DEV)
岡本(SM兼DEV)
ITサービス事業部
ソフトエンジニア歴25年くらい
Agile/Scrum歴は10年くらい?
 見澤(DEV)
見澤(DEV)
金融システム事業部
ソフトエンジニア歴15年くらい
Agileエンジニアにリスキル中
ScrumもPythonもGitもVSCodeもこの10月から触り始めました
 三田村(DEV)
三田村(DEV)
金融システム事業部
銀行勘定系システム一筋35年
生粋のコボラー&ウォーターフォーラーから
Agileエンジニアにリスキル中
この12月から新しくジョインしました
やったこと
偏愛マップ
「自分について」何でもいいのでひたすら書き出し、それをお互いに説明し合います。
今回はマインドマップの形で書き出してみました。
普通の自己紹介ではなかなか出てこないようなDeepな情報とか、それに対するツッコミが生まれてなかなか楽しいです。
口頭だと流れてしまうこともマップとして視覚化されていると強く意識に残るのと、終わった後に何回でも見直せるのが良いですね。
あと内容だけでなく、マップの書きっぷりにもそれぞれの個性が表れるなって思いました。
6人(チームの4人とPOの岡島さん、社長の平鍋さんも)でやって2時間近く盛り上がりました。
ちなみに6人中3人がギタリストだったことが判明しました。
せっかくなので全員の画像を貼ってみます。
雰囲気だけでも察してもらえると。
坂部さん

岡本

見澤さん

三田村さん

ドラッガー風エクササイズ
次の質問に対する回答を自分で作成して、それをお互いに紹介し合います。
- 自分は何が得意なのか?
- どういう風に仕事するか?
- 自分が大切に思う価値は何か?
- 自分にとっての地雷は何か?
- チームメンバーは自分にどんな成果を期待していると思うか?
- 他のチームメンバーに期待することは何か?
こちらも結局2時間くらいチームでワイワイと盛り上がりました。
なかなかにタフな質問で改めて聞かれるとすぐに答えが出てこないのですが、答えにくいなりに悩む過程とかそこから出てきた言葉にその人の個性が出てくるような気がします。
あとは短い付き合いながらも既に出来かけていたチームメンバへの印象というか先入観が結構あてにならず、「この人ってこんなこと考えていたんだ~」という発見がいくつもあってビックリしました。

やってみて
どちらも目新しいものではなく、岡本も前から知ってはいたのですが、ちゃんとした形でチームビルドとしてやってみたのは初めての経験でした。
正直に言うと、この手のエクササイズは苦手で、何かウサンクサイというか芝居がかった会話をする気恥ずかしさもあって(セミナーとかでよくやらされますよね)避けていたのですが、やってみると面白かった&得るものが多くて、やって良かったと思います。
メンバのみなさんも「やって良かった」「楽しかった」と言ってくれてるのでホッとしています。(社交辞令でないことを祈る)
多分ですが、偏愛マップとかドラッガー風エクササイズとかの個々の成果物というよりは、それを書き出したり説明しあう場に生まれる「会話」に本当の価値があるような気がします。
なので後から成果物だけを共有してもあまり意味はなくて、一緒に集まって会話することが大事なんだろうな、って思いました。
オンボーディング(12月に追加実施)
メンバ紹介の所にも書きましたが、金融システム事業部の三田村さんだけは業務都合によりこの12月から後追いでジョインする形になっています。
そこで改めてチームの足並みを揃える意味でオンボーディング(新規メンバの受け入れ)をやりました。
内容は基本的に10月にやったのと同じように
- FDP活動のゴール共有
- チームの現状説明 to 三田村さん
- ドラッガー風エクササイズ(第2回)
- 12月からのチーム運営ルールを全員で考える
みたなことをやりました。
オンボーディングではあるのですが、先行しているチームに新しくメンバが追加されるのではなく、4人で新しいチームを立ち上げるような意識で臨みました。
もちろん完全にフラットな状態に戻っての再スタートではありませんが、「先行&後発メンバ間の境界をなくしたい」という意図がチーム内で共有できたのは大きな成果かな、と思います。
チームビルドの大切さ
「プロジェクトの成否(の大部分)はチームで決まる」って思っているので、10月から新チームを立ち上げると決まってからは、「最初のチームビルドに全力投球する」と決めて自分なりにいろいろ考えたり準備を進めてきました。
まずは最初のスタートがなんとか形になったので、良かったな~と胸を撫でおろしている所です。
この後もメンバのみなさんと力を合わせて、来年の42期FDP終了時には、「これで解散するのが惜しい!」と思えるようなチームにしていきたいと思います。
よろしくお願いします!
VS Code Remote Containerで、自分用の拡張機能をインストールしたい
こんにちは。永和システムマネジメント FDPメンバの坂部です。
WSL2 + Docker + VS Code Remote Developmentでdotfilesの設定が反映されない〜と唸っていたところ、それとは無関係ですが、便利な設定を見つけました。既に知っている人も多いと思いますが、わたしはつい先ほど知りました…
わたしたちのチームは、VS Code Remote Developmentを介して、ローカルコンテナ上で開発しています。もちろん、Dockerfileやdevcontainer.jsonもチームで共有しています。コンテナ内で使うVS Code拡張機能についてもdevcontainer.jsonで管理して、共有しているのですが、それ以外の拡張機能を使いたくなるときってありますよね?
.devcontainer/devcontainer.json
{ ..., "extensions": [ "esbenp.prettier-vscode", "ms-python.python", "ms-toolsai.jupyter", "bungcip.better-toml" ] }
わたしは、GitLens、Git Graph、GitHub Pull Requests and Issues、Code Spell Checker あたりを愛用しているのですが、今までこれらはコンテナビルド後に手動でインストールしていました。
これって実はVS Codeの設定で指定できるようです。今まで知りませんでした…
Userのsettings.json
{ ..., "remote.containers.defaultExtensions": [ "github.vscode-pull-request-github", "eamodio.gitlens", "mhutchie.git-graph", "streetsidesoftware.code-spell-checker" ] }

これで、コンテナビルド毎に手動でインストールする手間が省けました 🎉
参考
【自己紹介】三田村 岳周
はじめまして
FDPメンバーの三田村です。
私は金融システム事業部の所属で、FDPには今月、12月1日から参加しました。
今期のメンバーは10月1日から岡本さん、坂部さん、見澤さんの3人でスタートしていますので、私は2ヵ月遅れての参加です。
FDOの活動について
このプロジェクトでは、まず、12月末まで勉強期間ということで、Pythonプログラミングや機械学習、それらを駆使したAI、データサイエンスの分野の学習に取り組んでいます。
と、言っても私は銀行勘定系システム一筋35年、開発言語はコボル、手法はウォーターフォールONLY。日々、頭にたくさんのはてなマークを抱えながらも、チームの仲間からの温かいサポートを受けながら、毎日が矢のように走り去っている状況です。
よろしくお願いします!!
いよいよ来月(1月)から、具体的なプロダクトをターゲットに設定して進んでいきます。
社員の皆さんが興味を持っていただけるような活動成果に繋がっていければいいなと、岡島POと共にメンバー全員で考えています。皆さんからの気軽な声かけや、様子見に来ていただけると嬉しいです。
【自己紹介】見澤久美子
はじめまして
こんにちは。まずは、自己紹介です。
永和システムマネジメントFDPメンバの見澤久美子です。
金融システム事業部所属です。
FDPへの気持ち
機械学習も、Pythonも、統計(数学)も、在宅勤務も、すべてが初めてです。 何も分からない状態でのスタートです。
いろんな不安もありますが、「やるぞ!」って前向きな気持ちは十分にあるので、 その気持ちを大切にし、精一杯学び、メンバと一緒に楽しく取り組んでいきたいと思っています。
よろしくお願いします
在宅勤務(出社は週1回)なので、顔を合わせることは少ないかもしれませんが、 見かけたら、いつでもどこでも気軽に声をかけてください。
TensorFlowをDockerコンテナ上で動作させるために、M1 MacからWindowsに移行した
こんにちは。永和システムマネジメント FDPメンバの坂部です。
M1 MacでTensorFlowをDockerコンテナ上で動作させるときに、色々ハマり、結局Windowsに移行したので、その経緯をお話しします。
前提
- チームメンバ4人中、3人はWindows。わたしだけM1 Mac。
- VS Code Remote Developmentを介して、ローカルコンテナ上で開発。Dockerfileもチームで共有。
- どうしてもTensorFlowを動作させたい。代替ライブラリは検討せず。
環境
- Python : 3.9.7
- TensorFlow : 2.7.0
TensorFlowのインストールでエラー
まずは、TensorFlowの公式ページを読んで、Pythonパッケージとして普通にインストールできることを知り、インストールを試みました。
ちなみに、poetryを使っています。
poetry add tensorflow
すると、RuntimeErrorが…
Skipping virtualenv creation, as specified in config file.
Using version ^2.7.0 for tensorflow
Updating dependencies
Resolving dependencies... (55.7s)
Writing lock file
Package operations: 31 installs, 1 update, 0 removals
• Updating charset-normalizer (2.0.7 -> 2.0.9)
• Installing pyasn1 (0.4.8)
• Installing cachetools (4.2.4)
• Installing oauthlib (3.1.1)
• Installing pyasn1-modules (0.2.8)
• Installing rsa (4.8)
• Installing zipp (3.6.0)
• Installing google-auth (2.3.3)
• Installing importlib-metadata (4.10.0)
• Installing requests-oauthlib (1.3.0)
• Installing absl-py (1.0.0)
• Installing google-auth-oauthlib (0.4.6)
• Installing grpcio (1.43.0)
• Installing markdown (3.3.6)
• Installing protobuf (3.19.1)
• Installing tensorboard-data-server (0.6.1)
• Installing tensorboard-plugin-wit (1.8.0)
• Installing werkzeug (2.0.2)
• Installing astunparse (1.6.3)
• Installing flatbuffers (2.0)
• Installing gast (0.4.0)
• Installing google-pasta (0.2.0)
• Installing h5py (3.6.0)
• Installing keras (2.7.0)
• Installing keras-preprocessing (1.1.2)
• Installing libclang (12.0.0)
• Installing opt-einsum (3.3.0)
• Installing tensorboard (2.7.0)
• Installing tensorflow-estimator (2.7.0)
• Installing tensorflow-io-gcs-filesystem (0.23.1): Failed
RuntimeError
Unable to find installation candidates for tensorflow-io-gcs-filesystem (0.23.1)
at /usr/local/lib/python3.9/site-packages/poetry/installation/chooser.py:72 in choose_for
68│
69│ links.append(link)
70│
71│ if not links:
→ 72│ raise RuntimeError(
73│ "Unable to find installation candidates for {}".format(package)
74│ )
75│
76│ # Get the best link
• Installing termcolor (1.1.0)
Failed to add packages, reverting the pyproject.toml file to its original content.
しかし、Windowsユーザのチームメンバに確認してもらうと、Windowsマシンではインストールが成功するとのこと。
TensorFlowのPythonパッケージ一覧を確認すると、x86_64の記述しかないので、どうやらARM64に対応していないようです。
ちなみに、Pythonパッケージ以外に、Dockerイメージでの提供もあるのですが、こちらもAMD64向けのイメージしかありません。
AMD64イメージを使ってみる
では、コンテナイメージをARM64じゃないものにすればよいのでは、と考えました。
実は、今までDockerイメージのアーキテクチャについて気にしたことはありませんでした。今回、勉強する良い機会と捉えて、軽く調べることにしました。
Dockerイメージのアーキテクチャは、Dockerfileで指定できるようです。
FROM --platform=linux/amd64 python:3.9.7
指定しない場合は、Dockerを実行しているマシンのOSやアーキテクチャに合うアーキテクチャが選択されます。同じpython:3.9.7を指定しても、マルチアーキテクチャという仕組みで、それぞれのアーキテクチャ用のイメージが選択されます。
明示的にlinux/amd64を指定してコンテナをビルドし、poetry add tensorflowしてみました。すると、インストールに成功しました。
やったーと喜んだも束の間、実際にPythonでTensorFlowをimportしようとすると、下記のエラーが発生しました。
The TensorFlow library was compiled to use AVX instructions, but these aren't available on your machine. qemu: uncaught target signal 6 (Aborted) - core dumped
QEMUは、Docker Desktop for Apple siliconで使われているエミュレータです。
下記Issueをざっと眺めましたが、AVXという拡張命令セットがQEMUでサポートされていないことが原因のようです。
Docker Desktop for Apple siliconについてのドキュメントを読んでいると、“best effort”という馴染みのある単語が目に入ってきました。
Not all images are available for ARM64 architecture. You can add --platform linux/amd64 to run an Intel image under emulation. In particular, the mysql image is not available for ARM64. You can work around this issue by using a mariadb image.
However, attempts to run Intel-based containers on Apple silicon machines under emulation can crash as qemu sometimes fails to run the container. In addition, filesystem change notification APIs (inotify) do not work under qemu emulation. Even when the containers do run correctly under emulation, they will be slower and use more memory than the native equivalent.
In summary, running Intel-based containers on Arm-based machines should be regarded as “best effort” only. We recommend running arm64 containers on Apple silicon machines whenever possible, and encouraging container authors to produce arm64, or multi-arch, versions of their containers. We expect this issue to become less common over time, as more and more images are rebuilt supporting multiple architectures.
https://docs.docker.com/desktop/mac/apple-silicon/#known-issues より
どうやら、ARM64以外のアーキテクチャのイメージを利用することは可能ですが、エミュレーションは完全じゃないようです。
M1 MacでTensorFlowを動作させたいだけなら
M1 MacでTensorFlowを動作させたいだけなら、TensorFlowをARM64向けにビルドすることで実現できます。
自前でビルドするのは、考慮事項が多く大変ですが、先駆者がARM64向けのDockerイメージを配布してくれています。
ただ、同イメージはAMD64には対応しておらず、チームでDockerfileを共有しているわたしたちには扱いにくいです。
また、ARM64向けのイメージビルドだけでも考慮することが多いので、ARM64 / AMD64両対応のイメージを自前でビルドすることは現実的でないと判断しました。
色々調べたが、Intelマシンに移行するのが手っ取り早そう
他にもLimaでIntel on ARMすればいけるのでは?と思い試したりしましたが、だめでした。
調査が長引いてきて、これ以上M1 Macでの動作に挑戦するより、Windowsに移行する方が適切と判断しました。
MacでもIntel Macなら問題ないと思いますが、既にチームでWindowsが普及していたこと、社内でWindowsの方が調達しやすそうなことから、Windowsを選択しました。
今後の動向
ARM64向けのPythonパッケージを配布して欲しいというIssueは存在します。
https://github.com/tensorflow/tensorflow/issues/52973
わたしはWindowsに慣れておらず、Macに戻りたいなーと思っているので、今後も関連Issueに注目していきたいです。