教師あり学習で分類をやってみた
はじめに
Agile Studioの岡本です。
毎回自己紹介の文言が揺れている気がします。
坂部さんが書いてくれたこちらの続きです。
前回はクラスタリングでしたが、今回は分類をやってみます。
クラスタリングと分類
クラスタリング
与えられた情報を、データの持つ特徴からいくつかのグループに分ける。
どう分けるか?は指示できず、分けた結果にも絶対的な正解はない。
(なので前回の結果も全体を眺めて「何となく良さそう」位しか言えない)
正解がないので「教師なし学習」の一種
分類
与えられた情報を、事前に正解が決まっているどのラベルに所属するか予測する。
正解があるので「教師あり学習」の一種
ながれ
まず最初に、全体の流れはこんなイメージです。
以下、これに沿って説明していきます。

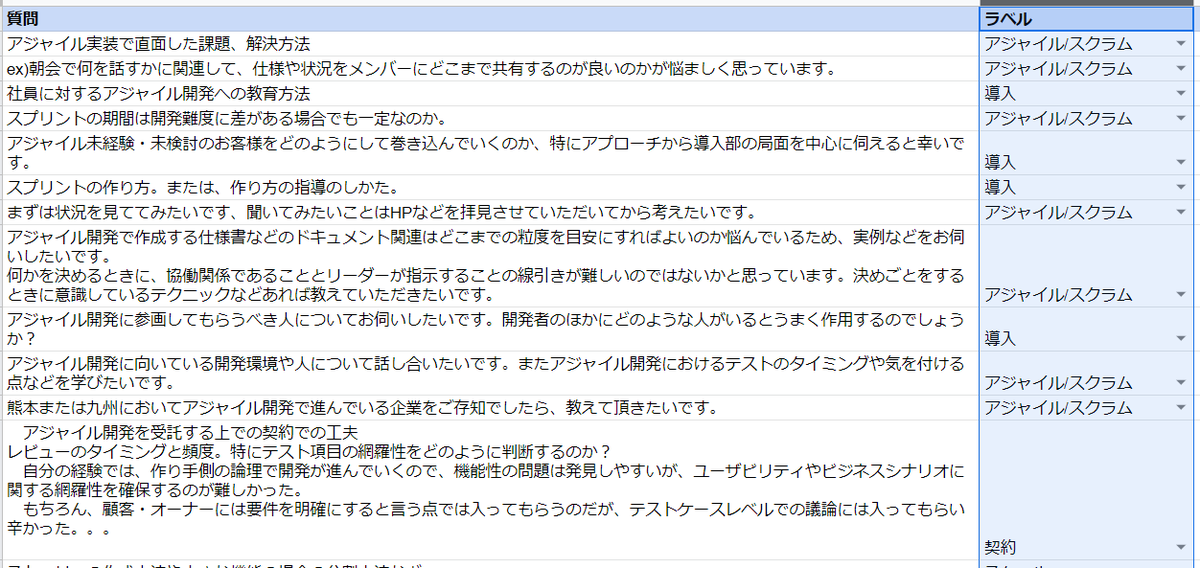
質問に対してラベル(正解となる分類)を付ける
まずは各質問に対して、「どのように分類されるべき」というラベルを設定します。
これは人間が手作業で行うため、作業者の主観が入ることもあり、正直一番難しい所です。
(後で思い知ることになります)
今回は岡本が独断で以下のような 10 個の分類を行いました。
- 契約
- 品質
- ウォーターフォール
- チーム
- ロール
- マネジメント
- 導入
- スケール
- アジャイル/スクラム
- リモート
手で入れた(ここはエクセル仕事です。。)
(途中省略)
質問を整形/分割して単語を抜き出すまでの処理は、前回のクラスタリングと共通なので説明は省略します。
ラベルを数値化する
ラベルを数学的に扱うために数値化します。
機械学習用語で「カテゴリ変数をダミー変数化する」とも言います。(難しい言い方だ)
ダミー変数化する方法として、pandas の get_dummies を用いるOne hot Encodingがあり、ググるとこれが多くヒットしますが、多値変数を扱う場合には複数のダミー変数が出現してしまうのであまり望ましくないらしいです。
そこでここでは Label Encoding によるダミー変数化を行います。
sklearn に専用のライブラリがあるのでそれを使えば簡単です。
これだけで OK
le = preprocessing.LabelEncoder() df['label'] = le.fit_transform(df['ラベル'].tolist())
こうなる

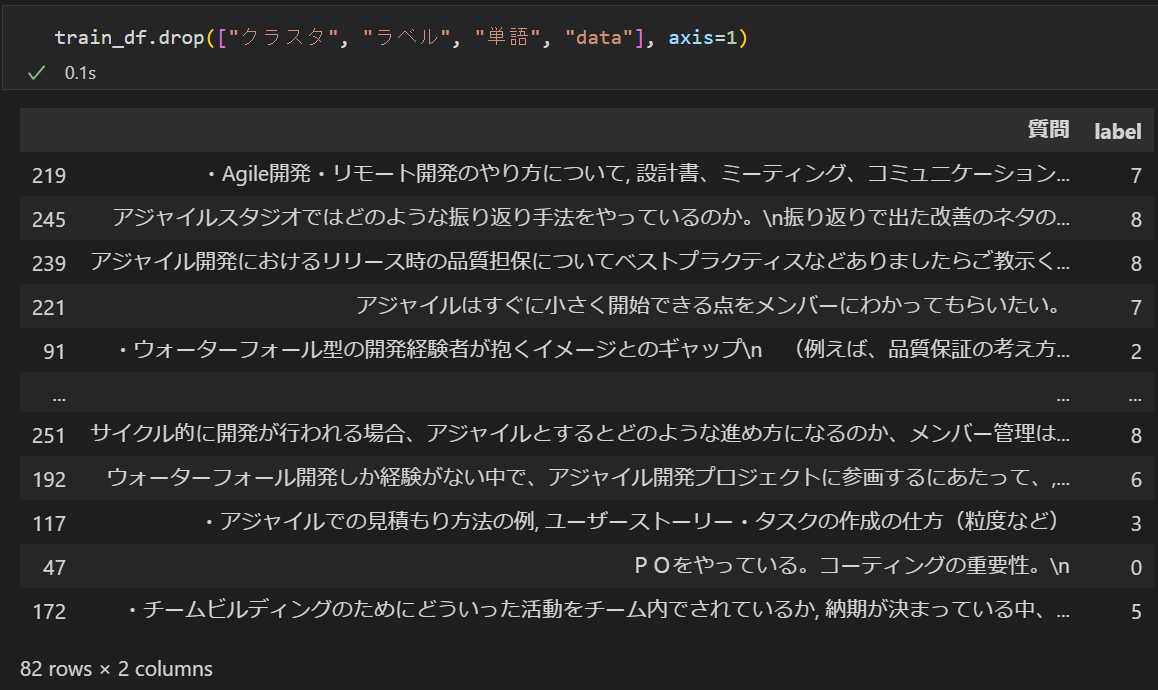
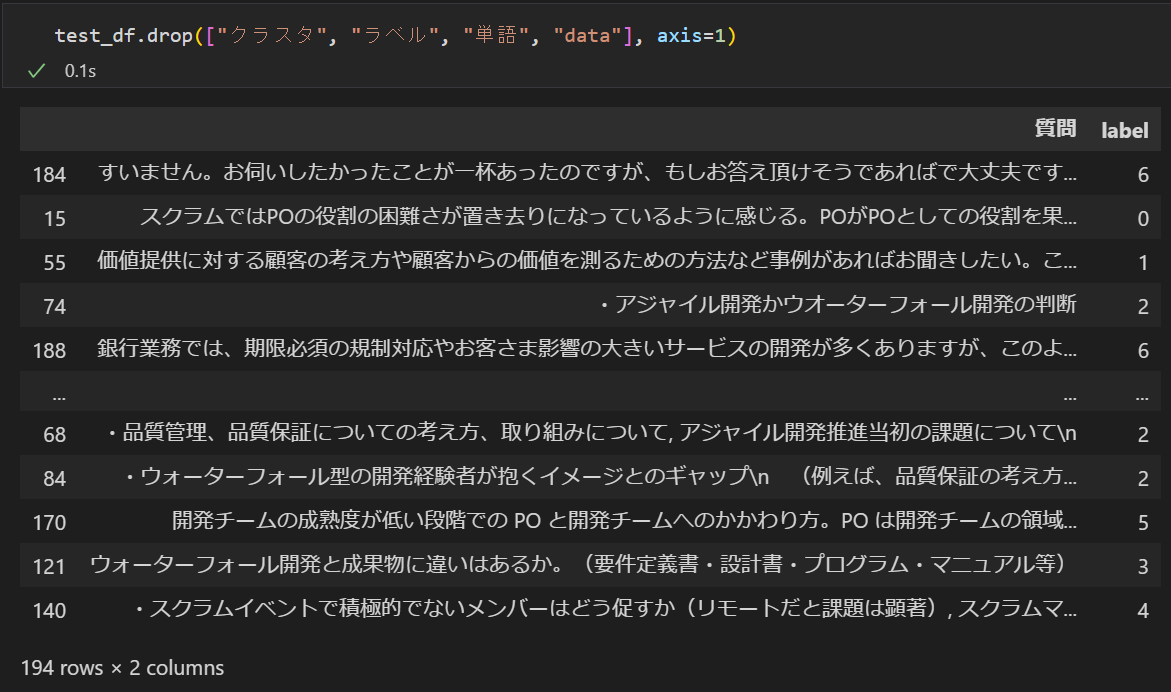
教師データとテストデータに分割する
全体を
- 教師データ:モデル学習のために使う部分
- テストデータ:学習した結果の評価(答え合わせ)に使う部分
に分割します。
またこれだけ。
train_df, test_df = train_test_split(df, random_state=0, train_size=0.3)
詳細は分からなくても何となくやっていることが想像できると思います。
質問をベクトル化して学習する
ベクトル化
質問(正確には質問から抽出した単語の集まり)も数学的に扱うために数値化します。
ラベルのように単純な数値化(10 種類のラベルを 0 ~ 9 に割り当てる)のではなく、質問の持つ特徴を抽出する必要があり、これをベクトル化と言います。
ベクトル化にはいろいろな手法(アルゴリズム)があるのですが、ここでは簡単に質問の中に登場する回数を特徴として抽出する CountVectorizer という手法を利用します。
学習
更にベクトル化した質問とそのラベルの対応関係を学習してモデルを構築します。
この学習の手法(アルゴリズム)もいろいろあり、データの特性にあった選択をするのがキモのようです。
ここではscikit-learn アルゴリズム・チートシート scikit-learn.org
を参照して ナイーブベイズ法 を使うことにします。
長々と説明しましたがコードはこれだけです(scikit-learn のライブラリがすごい)
model = make_pipeline(CountVectorizer(), MultinomialNB()) model.fit(train_df['data'], train_df['label'])
学習したモデルを使って分類(予測)を実行する
モデルができたので、これを使って実際に分類してみます。
分類は、モデルの学習に使わなかった方(テストデータ)で行って評価するのですが、モデルの良し悪しを見るために教師データの方でもやってみます。
教師データの分類実行と評価
train_df['pred'] = model.predict(train_df['data']) train_score = model.score(train_df['data'], train_df['label']) print(f'教師データのスコア:{train_score}')
評価結果
教師データのスコア:0.9512195121951219
教師データの分類実行と評価
test_df['pred'] = model.predict(test_df['data']) test_score = model.score(test_df['data'], test_df['label']) print(f'テストデータのスコア:{test_score}')
評価結果
テストデータのスコア:0.5
スコアの見方
0 ~ 1 の間で数値の大きい方が優秀(正解率が高い)です。
モデルを作るのに使った教師データなので、これを予測すれば100%正解しそうなものですが、そうはならないようです。
一方で答えの分かっていないテストデータに対しては、かなり正解率が落ちてしまっています。
これは、教師データの特徴を過度に学習してしまい、その他のデータに対して汎用的には使えないようなモデルになっている可能性を示しています。
この状態を「過学習」と言います。
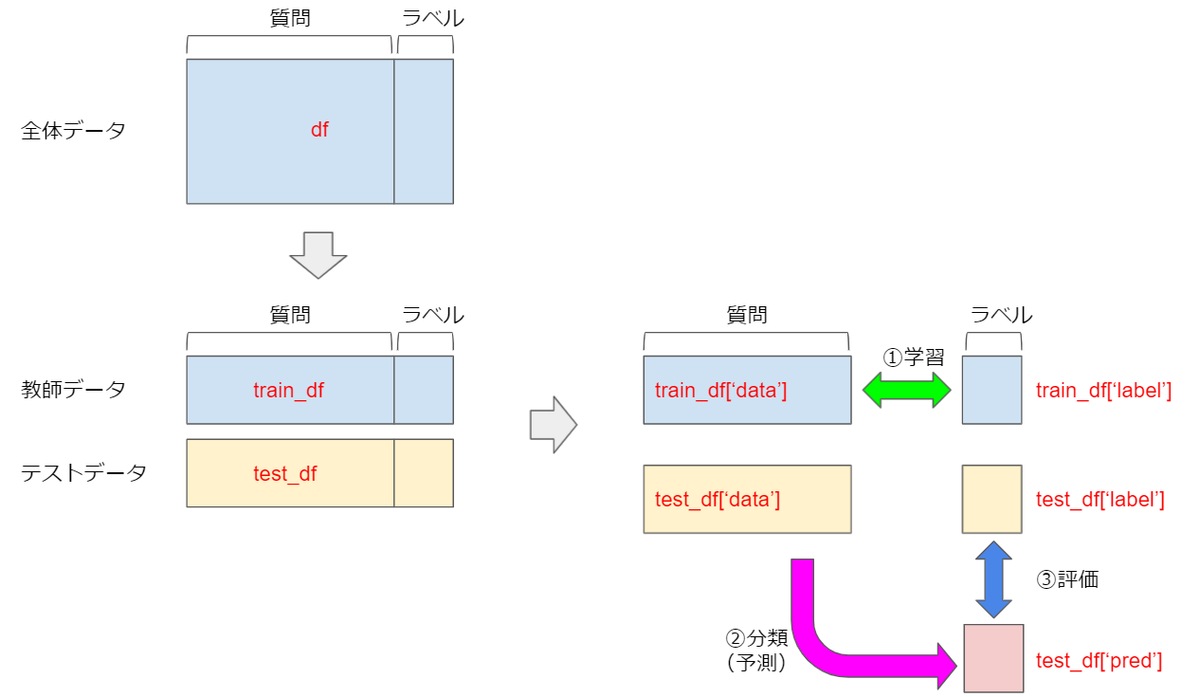
データの流れ(再掲)
コードとの対応関係を記したデータの流れを再度記載しておきます。
分類結果を評価する
これだけではモデルの良し悪しが分かりにくいので、正解ラベルと予測ラベルの対応を混同行列を使って描画してみます。
ここでは seaborn
というグラフライブラリを使っています。
またもこれだけ。
mat_train = confusion_matrix(train_df['label'], train_df['pred'])
mat_test = confusion_matrix(test_df['label'], test_df['pred'])
左が教師データ、右がテストデータの分類結果です。

グラフ(混同行列)の見方
横軸が正解ラベル、縦軸が分類(予測)されたラベルになっています。
予測結果が正解と同じだと対角線上に綺麗にプロットされることになります。
左の教師データは割と綺麗ですが、右のテストデータは多くの質問を1のラベルだと誤判定しています。
上で求めたスコアの傾向とも一致していて、あまりよろしくない結果のようです。
ちょっと考察
分類の精度が悪い理由は色々と考えられます。
- 学習対象のデータ量が少ない
- 学習対象のデータに有意な特徴がない
- ベクトル化のアルゴリズム選定、パラメータ調整が悪い
- 学習のアルゴリズム選定、パラメータ調整が悪い
- 人間がやったラベル付けが悪い(!!!)
本来であればこれらに対しての分析&トライを繰り返して精度を上げていく(そのためにも分類の良し悪しを定量的に測定できるスコアがとても大事)のですが、今回は時間がない事もあり、そもそも一番怪しいと思われる 『人間がやったラベル付けが悪い』 を疑ってみます。
別のアプローチを試してみる
前回のクラスタリングで、機械学習によってクラスタリングを行った結果、まあまあ良さげなグループ分けが出来ていました。
そこで、岡本が付けたラベルの替わりに、このグループ分けの結果を正解ラベルとして使ってみます。
具体的にはこの 1 行を変更します。
これを
df['label'] = le.fit_transform(df['ラベル'].tolist())
こうする
df['label'] = le.fit_transform(df['クラスタ'].tolist())
クラスタの列には前回のクラスタリングで得られたグループ情報が入っています。
再度評価してみる
評価結果(教師データ)
教師データのスコア:0.9634146341463414
評価結果(テストデータ)
テストデータのスコア:0.6185567010309279
教師データはそれほど変化しませんがテストデータは大きく向上しています。
続いて混同行列も見ます。
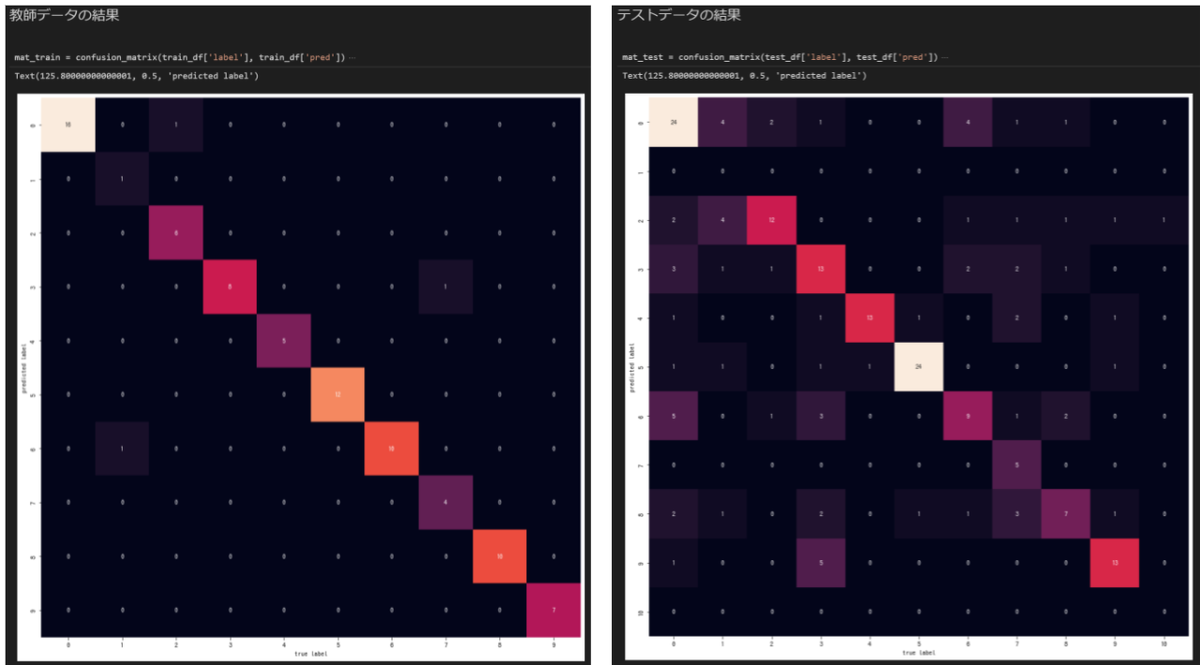
こんどは右のテストデータでも、そこそこ綺麗に対角線上に乗っていて、前回よりも精度が上がったように見えます。
やはり人間の行ったラベルに付けに問題があったようです。
感想
- scikit-learn のライブラリはすごい
データ処理やグラフ描画を除いた機械学習の本体はここに記載した数行のコードで実行できます。
「機械学習をやるなら Python」と言われている理由が良く分かります。 - Pythonのプロになる必要はない
機械学習で必要になるのは、使うライブラリをインポートして、そのライブラリを良い感じに使って、処理をコンパクトにするために簡単な繰り返しや条件分岐の構造が書ける、位です。
Python初学者でも問題なくトライできます(他の言語を触ったことがあれば尚更) - 数値化/評価まで含めた自動実行の仕組み大事
最後は精度向上のためにトライ&確認を繰り返すことになるので、評価までが自動で行えるかどうかが作業効率にモロに効いてきます。
初回は面倒でも手作業を無くしてコード化して置くことが大事です(ユニットテストと同じですね) - 人間の作業が一番信用ならない
ラベル付けに限らずデータの整形(クリーニング)など、機械学習の前段で行う作業によって結果が大きく変わってくるので、意外に原始的な作業の良し悪しが大事かも。
次回
次は回帰にチャレンジしているので、また一段落したら別の記事に書こうと思います。
ツールから見るFDPのリモートワーク事情
こんにちは。永和システムマネジメント FDPメンバの坂部です。
今回は、私たちチームがツールをどのように使ってリモートワークしているか、お話しします。
Slack
Slackはこんな感じです。

主なチャンネルはこんな感じです。(boatってのはチーム名です)
| チャンネル名 | 用途 |
|---|---|
| team42-boat | 全体チャンネル。業務連絡や雑談は全部ここ。 |
| team42-boat-log | 1日の終わりに、その日やったことを書くチャンネル。次の日の朝会で見返す。 |
| team42-boat-notification | GitHubやこのブログの更新通知を送るチャンネル。 |
| times-<名前> | メンバそれぞれのつぶやきチャンネル。 |
多分、そこまで凝ったことはしていないと思います。
唯一特徴的なこととして、スレッドによる返信を非推奨にしています。
メンバ全員が今までSlackをガッツリ使ったことがなかったので、スレッドの返信に慣れておらず、見逃しやすいというのが理由です。小さいチームなので、スレッドなしでもチャンネルがごちゃつくことはありません。
Zoom
チームでは、Zoomで常時接続しています。
質問や共有事項があれば、「ちょっといいですか?」と声をかけることができます。個人作業のときは、接続していても会話せずに作業に没頭しています。
常時接続は、コミュニケーションには便利なのですが、一人で集中したいときにはマイナスになることもあります。よって、強制はしておらず、自由にZoomを抜けることができます。特に私が抜けていることが多いです

GitHub
コード管理はもちろんのこと、カンバンを中心としたタスク管理にもGitHubを使っています。
詳しくはこちらをどうぞ。
Miro
ふりかえりにはオンラインホワイトボードのMiroを使っています。
ストックすべき情報はGitHubを中心に管理していますが、ふりかえりをはじめとして、ディスカッションやチームビルディングなど、気軽にふせんをペタペタしたいときにはMiroが重宝します。

おわりに
どのツールも一長一短なので、自分達に合うツールを自分達で選定することが重要だと思います。
また、日々「こんなツール使ってみたい」「この機能を有効化したい」とチーム内で提案し、より良い使い方を模索していくことも必要だと思います。
今後もツールを使いこなして、効率的にリモートワークしていきたいです 💪
Agile Studio見学への要望を機械学習で分析してみた
はじめに
こんにちは。永和システムマネジメント FDPメンバの坂部です。
今回、Agile Studio 見学への要望のデータを、クラスタリングすることで分析してみました。
Agile Studioとは?
Agile Studioは、永和の、アジャイル開発を推進するサービスです。 企業様に向けて、仕事の様子を見たりアジャイル開発についてディスカッションしたりする見学会を開催しています。 今回分析するデータは、この見学の事前アンケートを元にしています。
やったこと
データを整形する
データを眺める
まずは、データを眺めました。
データは、見学する企業様ごとにスプレッドシートにまとまっています。
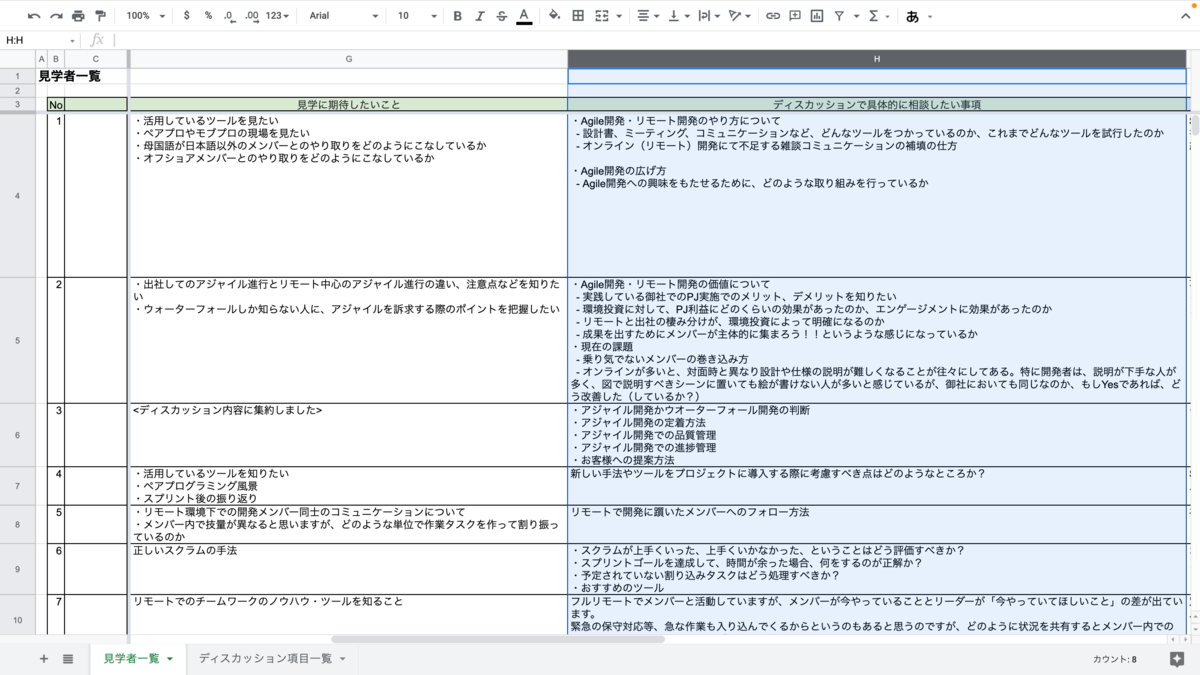
複数の項目があるのですが、今回は「ディスカッションで具体的に相談したい事項」について分析することにしました。 なお、これ以降、「ディスカッションで具体的に相談したい事項」は「質問」と呼ぶことにします。
データをファイルにまとめる
そこまで量がなかったので、手作業でスプレッドシートから「ディスカッションで具体的に相談したい事項」を抜き出し(as 質問)、一つのスプレッドシートにまとめ、csvでエクスポートしました。
質問を分割する
ここからPythonで作業していきます。
import pandas as pd # 先ほど作成したcsvを読み込む df = pd.read_csv('./data.csv', header=None, names=['質問']) df

スプレッドシートのセル一つ一つから抜き出しましたが、セル一つに複数の事項が存在するセルもあったので、下記のようなデータが含まれています。

これらは、コードで分割しました。
import re def split_to_single_question(target): for bullet_mark in '①', '②', '③', '-': target = target.replace(bullet_mark, '・') # 「・」の前に改行を含むものだけを対象として分割する。 # 含まないものは、箇条書きを意味する「・」ではないと捉えて、分割しない # 改行と「・」の間の半角スペースは無視する pattern = "\n\s*・" if re.search(pattern, target) is None: return [target] target_split = re.split(pattern, target) if target_split[0][0] == "・": return target_split else: # 箇条書き一つ前の文は、全ての箇条書きの先頭に付与する return [target_split[0] + ", " + t for t in target_split[1:]] split_questions = [] for questions in df["質問"]: for q in split_to_single_question(questions): split_questions.append((questions, q)) df = pd.DataFrame(split_questions, columns=["質問", "分割済み質問"]) df

また、下記のように永和からの回答が含まれている場合もあります。

これらは、コードにて回答の部分を削除しました。
def remove_response_from_eiwa(target): for response_mark in ["⇒(ESM)", "⇒ (ESM)", "→"]: target = target.split(response_mark)[0] return target df["分割済み返答削除済み質問"] = df["分割済み質問"].map(remove_response_from_eiwa) df

パターンの漏れがあり、これらで全ての質問を分割したり、全ての回答を削除したりはできませんが、 とりあえずヨシとします 👈🏼 🐱
クラスタリング
では、クラスタリングしていきましょう。
質問から単語を抜き出す
まずは、質問から単語を抜き出します。
今回は、Mecabという形態素解析エンジンで品詞に分解しました。 解析用の辞書はIPADICを採用しています。(実はIPADICはサポート終了してる 😭 )
分解後、名詞かつ意味のある単語だけを抜き出します。
import requests import MeCab import ipadic # 今回の処理において意味のない単語リスト(=ストップワード) stop_words = [] # ある程度のストップワードは、ここでリストが提供されている SLOTHLIB_URL = "http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt" stop_words.extend(requests.get(SLOTHLIB_URL).text.split("\r\n")) # slothlibで対応できないものは、手動で対応 stop_words.extend(['0', '1', '2', '3', '4', '5', '6' '7', '8', '9']) stop_words.extend(['0', '1', '2', '3', '4', '5', '6' '7', '8', '9']) stop_words.extend(['あ', 'い', 'う', 'え', 'お', 'か', 'き', 'く', 'け', 'こ', 'さ', 'し', 'す', 'せ', 'そ', 'た', 'ち', 'つ', 'て', 'と', 'な', 'に', 'ぬ', 'ね', 'の', 'は', 'ひ', 'ふ', 'へ', 'ほ', 'ま', 'み', 'む', 'め', 'も', 'や', 'ゆ', 'よ', 'ら', 'り', 'る', 'れ', 'ろ', 'わ', 'を', 'ん']) stop_words.extend(['が', 'ぎ', 'ぐ', 'げ', 'ご', 'ざ', 'じ', 'ず', 'ぜ', 'ぞ', 'だ', 'ぢ', 'づ', 'で', 'ど', 'ば', 'び', 'ぶ', 'べ', 'ぼ']) stop_words.extend(['方', '方法', 'こと', 'ため', '人', '性', '何', '等', '化', '場合', '点', '時', '工夫', '様', '中', 'とき', 'ところ', 'もの', 'それ', '書', '側', '内', '際', '以下', '20', '年', 'M', '内容', '作成', '.', 'どこ', '以外', 'つ', '目', 'さん']) stop_words.extend(['アジャイル', 'Agile', '開発']) # かなり多く出てくるので削除 mecab_tagger = MeCab.Tagger(ipadic.MECAB_ARGS) def parse_question_to_words(target): parsed_lines = mecab_tagger.parse(target).split('\n') parsed_words = [parsed_line.split('\t') for parsed_line in parsed_lines] words = [] for parsed_word in parsed_words: if len(parsed_word) > 1 and '名詞' in parsed_word[1]: target = parsed_word[0] # ストップワードに含まれない単語だけを取り扱う if not target in stop_words: words.append(target) return words df['単語'] = df['分割済み返答削除済み質問'].map(parse_question_to_words) df

質問をベクトル化する
単語をもとに、それぞれの質問をベクトル化していきます。
今回は、それぞれの単語の出現回数を、質問を表すベクトルとしました。
また、そのベクトルをtf-idfで重み付けしました。(tf-idfの説明は、自信ないのでwikipediaに任せます…)
from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer # ベクトル化 bags = CountVectorizer().fit_transform([" ".join(words) for words in df["単語"]]) # ベクトルを重み付け tf_idf = TfidfTransformer(use_idf=True, norm="l2", smooth_idf=True).fit_transform(bags)
質問をクラスタリングする
k-means法でクラスタリングしてみます。(この説明もwikipediaで…)
from sklearn.cluster import KMeans kmeans_model = KMeans(n_clusters=10, random_state=1) # クラスタ数は10で固定 result = kmeans_model.fit_predict(tf_idf)
結果を描画する
クラスタごとの要素数をグラフで見てみましょう。
import collections import matplotlib.pyplot as plt cluster_count = dict(collections.Counter(result).most_common()) cluster_count_sorted = sorted(cluster_count.items(), key=lambda x: x[0]) k = [f"クラスタ {k}" for k, _ in cluster_count_sorted] v = [v for _, v in cluster_count_sorted] plt.figure(figsize=(20, 20), dpi=50) plt.bar(k, v)
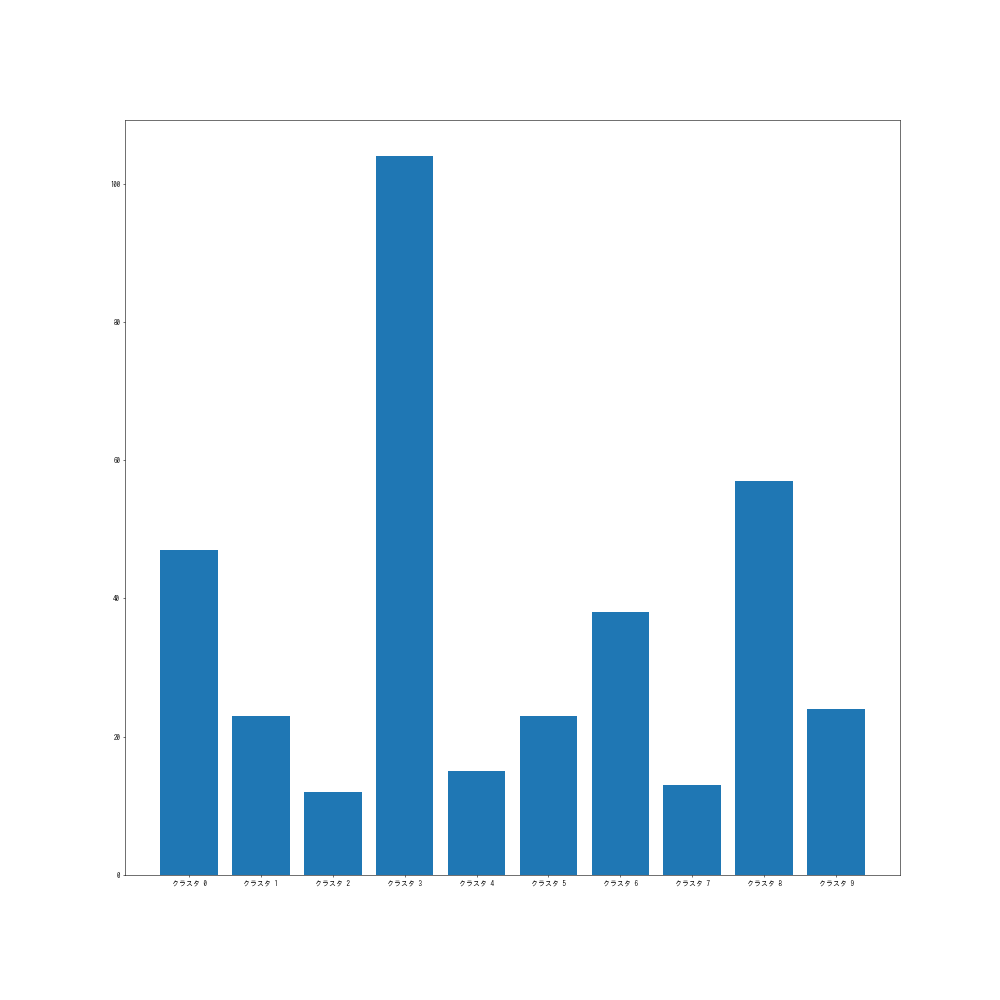
まあまあ分散した結果になったのではないでしょうか。
クラスタごとにどんな単語が含まれているか見てみましょう。
df["クラスタ"] = result cluster_words_dict = {} for i, row in df.iterrows(): cluster, words = row["クラスタ"], row["単語"] if cluster in cluster_words_dict: cluster_words_dict[cluster].extend(words) else: cluster_words_dict[cluster] = words cluster_commonwords_dict = {} for k, v in cluster_words_dict.items(): counter = collections.Counter(v) # クラスタの頻出頻度上位10単語を参照 cluster_commonwords_dict[k] = dict(counter.most_common(10)) fig, ax = plt.subplots(10, figsize=(50, 50)) for k, v in cluster_commonwords_dict.items(): ax[k].set_title(f"クラスタ {k}") ax[k].bar(v.keys(), v.values())
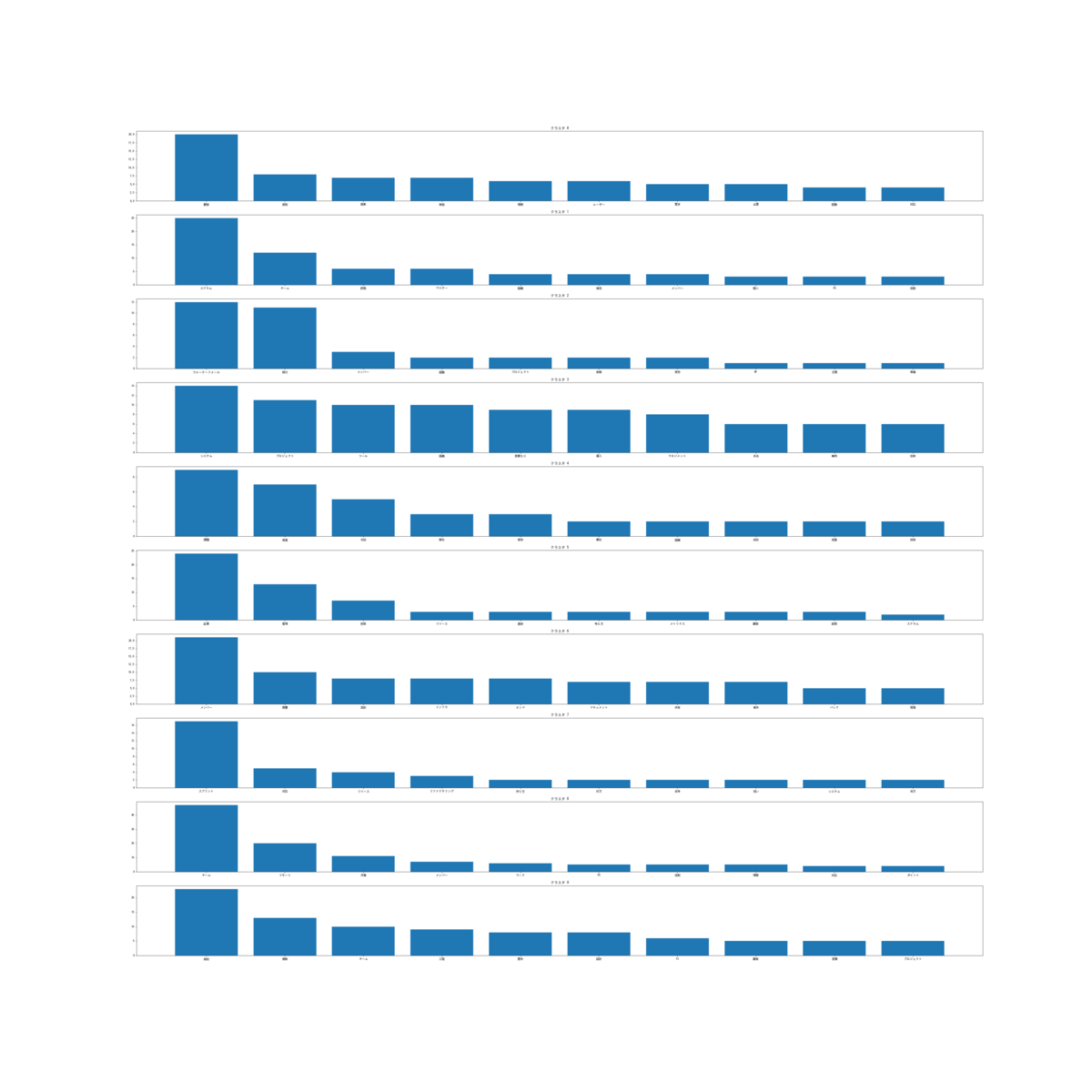
見辛いですね…ワードクラウドを描画してみましょう。
word_cloudを使います。
from wordcloud import WordCloud fig, ax = plt.subplots(nrows=4, ncols=3, figsize=(50, 50)) for k, v in cluster_commonwords_dict.items(): wordcloud = WordCloud().fit_words(v) ax_item = ax.ravel()[k] ax_item.set_title(f'クラスタ {k}', fontsize=100) ax_item.set_axis_off() ax_item.imshow(wordcloud, interpolation='bilinear')

なんとなく「クラスタ2はウォーターフォールからの移行に関して」「クラスタ8はリモートでのコミュニケーションに関して」など意味のあるクラスタになってそうですね。
感想
2週間、こちらの課題に取り組んでみたのですが、とりあえず一通りのプロセスを動かすために、アルゴリズムやコードの精査を省いています。それらを精査してもっと適切な方法を学びたいです。
また、実際に課題にトライすることで、機械学習プロジェクトの流れが少し掴めた気がします。
GitHub Projects Betaではじめるプロジェクト管理
こんにちは。永和システムマネジメント FDPメンバの坂部です。
今回は、私たちのチームで、カンバンツールGitHub Projectsの新バージョン、GitHub Projects Betaをどう使っているか、お話しします。
はじめに
私たちのチームは、FDPという特殊なプロジェクトに属しているので、アプリ開発に加えて、勉強や情報発信、イベント参加などもチームのタスクとして管理しています。
それに従い、現在リポジトリは3つになっています。
- 勉強・情報発信・イベント参加などのタスク管理用
- アプリ開発用
- アプリ開発のテンプレート用
アプリ開発用に関しては、2〜3ヶ月で一つのアプリを作り、それを何回か繰り返す予定なので、今後、アプリA開発用、アプリB開発用…と増える可能性があります。
今回、GitHub Projects Betaを採用することで、複数のリポジトリに存在する、さまざまなタスクを管理することができるようになりました。
どう使っているか
メインのカンバンはこんな感じです。
ここにはチームが関係するIssue、PRが全て存在します。

こちらは、アプリ開発用のカンバンです。
先程のカンバンに、リポジトリでフィルターをかけたものになります。
さまざまなタスクに取り組んでいるとはいえ、現在はアプリ開発がメインなので、作業中はこのカンバンを見ることが多いです。特に、朝会やスプリントプランニングでは、ここを中心に議論します。

こちらは、アプリのユーザーストーリーだけを表示しているカンバンです。
スプリントレビューやスプリントプランニングで、POとユーザーストーリーの優先度を議論するときに使います。POにとってはノイズになりうるタスクが見えないので、純粋にユーザーストーリーだけを対象にして議論できます。

こちらは、アプリのプロダクトバックログをリスト表示したものです。
GitHub Projects Betaでは、カンバン以外に、このようにリスト表示することもできます。 プロダクトバックログの優先度を決めて並び替えるときは、一度に多くのバックログを見ることのできるリストの方が便利です。

PRだけのカンバンも作れます。現在出ているPRの状態が一目でわかるので便利です。

まとめ
複数のリポジトリを横断するカンバンはGitHub Projects(=新バージョンじゃない方)でも作成できます。
しかし、リポジトリやラベルなどでフィルターする場合、GitHub Projects Betaは便利です。GitHub Projectsでもフィルターをかけることはできますが、GitHub Projects Betaではフィルターをかけた状態でViewとして固定できます。このViewを使い分けることで、普段見るカンバン、スプリントプランニングのときに見るカンバンなどを手軽に切り替えることができます。
また、リストはGitHub Projectsにはない機能です。カンバンは見やすいですが、縦に長いレーンはスクロールしないと見えない場合があります。そういったとき、リストは役立ちます。
今後
GitHub Projects Betaは、名前の通りまだベータ版であり、足りない機能もあります。
例えば、自動的なアイテムの移動(Workflows)は、プリセットを有効化することはできますが、カスタマイズまではできないです。
私たちのチームでは、IssueとPRは、追加されたらどちらも「プロダクトバックログ」レーンに移動します。PRは「In Progress」レーンに移動してほしいのですが、別々の設定はできないので、手動で移動させています。

ありがたく使いつつ、今後の動向を注視していきたいです。
Windowsの開発環境をセットアップしてみる
こんにちは。永和システムマネジメント FDPメンバの坂部です。
先日、MacからWindowsに移行しました。
今日は、私が行ったセットアップをふりかえってみようと思います。
設定したもの
- WSL
- Docker
- Git
- Homebrew
- zsh
- VS Code
ここには挙げていませんが、SlackやZoomも入れました。
WSL
まず、WSLを入れます。デフォルトではUbuntuがインストールされます。
powershell
# see https://docs.microsoft.com/ja-jp/windows/wsl/install wsl --install

以降は、WSLで作業します。
Docker
Dockerは、WSLに入れます。
最初はDocker Desktop for Windowsを使っていたのですが、有料化するので、WSLにインストールすることにしました。
WSL
# see https://docs.docker.com/engine/install/ubuntu/ # レジストリを設定 $ sudo apt-get update $ sudo apt-get install \ ca-certificates \ curl \ gnupg \ lsb-release $ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg $ echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null # Dockerをインストール $ sudo apt-get update $ sudo apt-get install docker-ce docker-ce-cli containerd.io
Hello Worldしてみます。
WSL
# Dockerデーモンを起動 $ sudo service docker start * Starting Docker: docker # Hello World $ sudo docker run hello-world Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 2db29710123e: Pull complete Digest: sha256:2498fce14358aa50ead0cc6c19990fc6ff866ce72aeb5546e1d59caac3d0d60f Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal. To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/ For more examples and ideas, visit: https://docs.docker.com/get-started/
問題なさそうですね。
後ほどVS Codeを使うときに問題になるので、Dockerをルートユーザ以外で扱えるようにします。
WSL
# see https://docs.docker.com/engine/install/linux-postinstall/#manage-docker-as-a-non-root-user $ sudo groupadd docker $ sudo usermod -aG docker $USER
WSLを再起動すると、Dockerがsudo無しで使えるようになっています。
WSL
$ docker run hello-world Hello from Docker! This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal. To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/ For more examples and ideas, visit: https://docs.docker.com/get-started/
Git
Gitは既にインストールされていますが、バージョンが古いので新しくします。
WSL
# Gitのバージョンを確認する $ git --version git version 2.17.1 # 最新のGitをインストールする # see https://git-scm.com/download/linux $ sudo add-apt-repository ppa:git-core/ppa $ sudo apt update $ sudo apt-get install git # Gitのバージョンを確認する $ git --version git version 2.34.1
クレデンシャルを保存するために、Git Credential Managerを使います。
Git Credential ManagerはGit for Windowsに含まれているようなので、Git for Windowsをインストールします。

WSLに戻って、クレデンシャルマネージャを設定します。
WSL
# see https://docs.microsoft.com/ja-jp/windows/wsl/tutorials/wsl-git $ git config --global credential.helper "/mnt/c/Program\ Files/Git/mingw64/libexec/git-core/git-credential-manager-core.exe"
Homebrew
HomebrewはMac OSでよく使われるパッケージマネージャですが、Linuxでも使えます。 これ以降は、Homebrewでインストールしていきます。
WSL
# see https://docs.brew.sh/Homebrew-on-Linux # Homebrewをインストール $ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" ...略... ==> Installation successful! ==> Homebrew has enabled anonymous aggregate formulae and cask analytics. Read the analytics documentation (and how to opt-out) here: https://docs.brew.sh/Analytics No analytics data has been sent yet (nor will any be during this install run). ==> Homebrew is run entirely by unpaid volunteers. Please consider donating: https://github.com/Homebrew/brew#donations ==> Next steps: - Run these two commands in your terminal to add Homebrew to your PATH: echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> /home/hirokisakabe/.profile eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)" - Install Homebrews dependencies if you have sudo access: sudo apt-get install build-essential For more information, see: https://docs.brew.sh/Homebrew-on-Linux - We recommend that you install GCC: brew install gcc - Run brew help to get started - Further documentation: https://docs.brew.sh
# 上記の "Next steps" を参考にパスを通す $ echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> /home/hirokisakabe/.profile $ eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)" # パスが通っているか確認 $ which brew /home/linuxbrew/.linuxbrew/bin/brew
zsh
今までMac OSでzshを使っていたので、ログインシェルをbashからzshに変更します。
WSL
# zshをインストール $ brew install zsh # パスを確認 $ which zsh /home/linuxbrew/.linuxbrew/bin/zsh
ログインシェルの候補リストに、zshを追加します。
/etc/shells
# /etc/shells: valid login shells /bin/sh /bin/bash /bin/rbash /bin/dash /usr/bin/tmux /usr/bin/screen # 下記を追加 /home/linuxbrew/.linuxbrew/bin/zsh
WSL
# ログインシェルを変更 $ chsh -s /home/linuxbrew/.linuxbrew/bin/zsh
WSLを再起動するとzshへの変更が反映されています。
このあと少し使うので、.zshrcを作るために「0」を入力しておきます。
せっかくなので?zshのプロンプトテーマを設定してみます。
わたしは、pureをよく使ってます。
WSL
# bashに設定したHomebrewのパスを、zshにも設定する $ echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> /home/hirokisakabe/.profile $ eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)" # pureをインストール $ brew install pure
.zshrcを編集してpureを設定します。
.zshrc
# Created by newuser for 5.8 # see https://github.com/sindresorhus/pure # 下記を追加 autoload -U promptinit; promptinit prompt pure
WSL
# .zshrcの設定を反映 $ source .zshrc

pureが設定されました!!ちょっと見辛いかな…
VS Code
普通に公式サイトからインストールします。
FDPではVS Code Remote Containerを使っているので、問題なく動作するか、開発コンテナを立ち上げて確認してみます。
サンプルとして、 https://github.com/microsoft/vscode-remote-try-python を使います。
WSL
$ git clone https://github.com/microsoft/vscode-remote-try-python.git $ cd vscode-remote-try-python # カレントディレクトリでVS Codeを開く # see https://docs.microsoft.com/ja-jp/windows/wsl/tutorials/wsl-vscode#from-the-command-line $ code .
Reopen in Containerします。
開発コンテナを立ち上げることができました!!

おわり
↓ Dockerデーモンを自動で起動するようにしたり、dotfilesをMacOS用と共通化したり、やってみたいことはまだまだあります!!
参考
コマンドラインからカレントディレクトリをdevcontainerで開く
こんにちは。永和システムマネジメント FDPメンバの坂部です。
今まで、VS Code Remote Containerを使うときは、ターミナルで任意のディレクトリまで移動して、code .でVS Codeを開いてから、Reopen in Containerしていました…
devcontainer CLIをインストールすれば、devcontainer openすることで、Reopen in Containerを省略して、一発で、カレントディレクトリをdevcontainerで開くことができます。
# カレントディレクトリをdevcontainerで開く
$ devcontainer open
2022/01/12時点では、コマンドパレットからインストールしてください。

npm経由でもインストールできるのですが、現在、npm経由でインストールしたものはdevcontainer openコマンドが使えなくなっています。
Issue : https://github.com/microsoft/vscode-remote-release/issues/5957
ちなみに、このdevcontainer CLI。もう一つ、devcontainerのイメージをビルドするという機能があるのですが、今のところ使っていません。こちらの機能も使っていきたいなあ…
参考
教育目的プロダクトのプロダクトゴールをどう導くか
POの岡島です。
※ これは、「育てるAI検温(二期生版)」のプロダクトビジョン、および、プロダクトゴールを説明した文書です。今までメンバーに口頭で説明していたものを、これまでの経緯もふまえ整理しました。当然ハイコンテキストな読み物なのですが、世のScrumチームの何か役に立つ部分もあるかもと思い、ほぼそのまま、ブログエントリとして公開します。
まずは、FDPは今は二期生が活動中で、今から二期生は一期生と同様のビジョンで「育てるAI検温」というプロダクトを開発するんだ、ということだけ理解してもらえればうれしいです。PO視点でのFDPの説明については、以下エントリにあります。
続きを読む